
Google Americas Faculty Summit Day 2: Shopping, Coupons and Data
July 18, 2011
Posted by Andrew W. Moore, Director, Google Commerce and Site Director, Pittsburgh
On July 14 and 15, we held our seventh annual Faculty Summit for the Americas with our New York City offices hosting for the first time. Over the next few days, we will be bringing you a series of blog posts dedicated to sharing the Summit's events, topics and speakers. --Ed
Google is ramping up its commitment to making shopping and commerce fun, convenient and useful. As a computer scientist with a background in algorithms and large scale artificial intelligence, what's most interesting to me is the breadth of fundamental new technologies needed in this area. They range from the computer vision technology that recognizes fashion styles and visually similar items of clothing, to a deep understanding of (potentially) all goods for sale in the world, to new and convenient payments technologies, to the intelligence that can be brought to the mobile shopping experience, to the infrastructure needed to make these technologies work on a global scale.
At the Faculty Summit this week, I took the opportunity to engage faculty in some of the fascinating research questions that we are working on within Google Commerce. For example, consider the processing flow required to present a user with an appropriate set of shoes from which to choose, given the input of an image of a high heel shoe. First, we need to segment or identify the object of interest in the input image. If the input is an image of a high heel with the Alps in the background, we don’t want to find images of different types of shoes with the Alps in the background, we want images of high heels.
The second step is to extract the object’s “visual signature” and build an index using color, shape, pattern and metadata. Then, a search is performed using a variety of similarity measures. The implementation of this processing flow raises several research challenges. For example, the calculations required to determine similar shoes could be slow due to the number of factors that must be considered. Segmentation can also pose a difficult problem because of the complexity of the feature extraction algorithms.
Another important consideration is personalization. Consumers want items that correspond to their interests, so we should include results based on historical search and shopping data for a particular person (who has opted-in to such features). More importantly, we want to downweight styles that the shopper has indicated he does not like. Finally, we also need to include some creative items to simulate the serendipitous connections one makes when shopping in a store. This is a new kind of search experience, which requires a new kind of architecture and new ways to infer shopper satisfaction. As a result, we find ourselves exploring new kinds of statistical models and the underlying infrastructure to support them.
-
Labels:
- Education Innovation
Other posts of interest
-
March 19, 2024
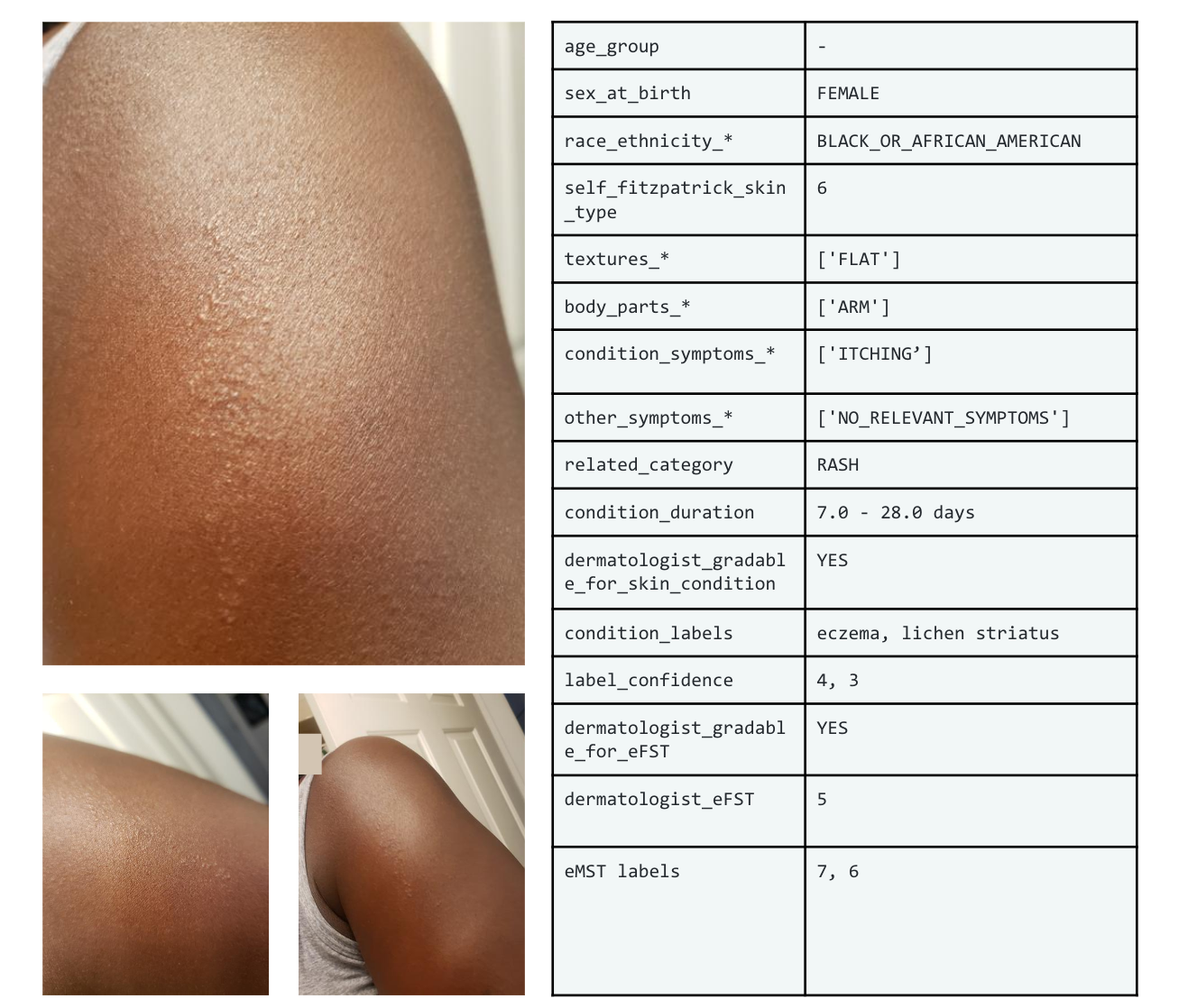
SCIN: A new resource for representative dermatology images- Education Innovation ·
- Health & Bioscience ·
- Open Source Models & Datasets
-

October 19, 2023
English learners can now practice speaking on Search- Education Innovation ·
- Product ·
- Speech Processing
-
October 26, 2022
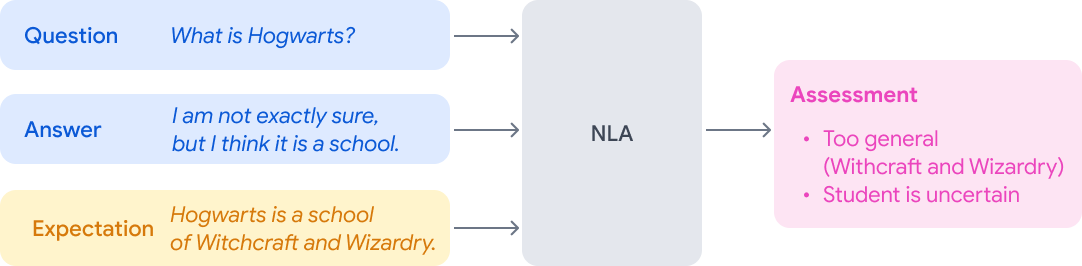
Natural Language Assessment: A New Framework to Promote Education- Education Innovation ·
- Natural Language Processing