Google’s Next Generation Music Recognition
September 14, 2018
Posted by James Lyon, Google AI, Zürich
Quick links
In 2017 we launched Now Playing on the Pixel 2, using deep neural networks to bring low-power, always-on music recognition to mobile devices. In developing Now Playing, our goal was to create a small, efficient music recognizer which requires a very small fingerprint for each track in the database, allowing music recognition to be run entirely on-device without an internet connection. As it turns out, Now Playing was not only useful for an on-device music recognizer, but also greatly exceeded the accuracy and efficiency of our then-current server-side system, Sound Search, which was built before the widespread use of deep neural networks. Naturally, we wondered if we could bring the same technology that powers Now Playing to the server-side Sound Search, with the goal of making Google’s music recognition capabilities the best in the world.
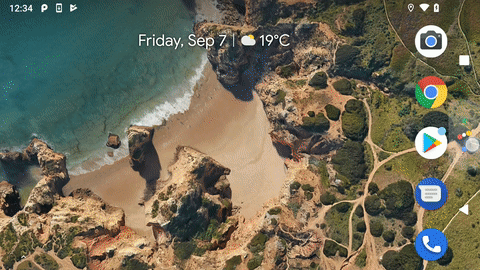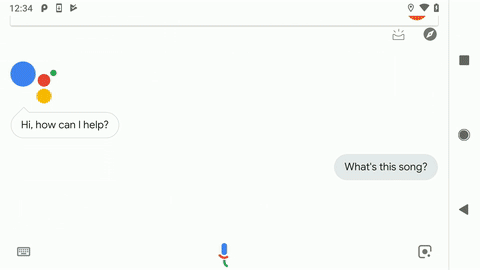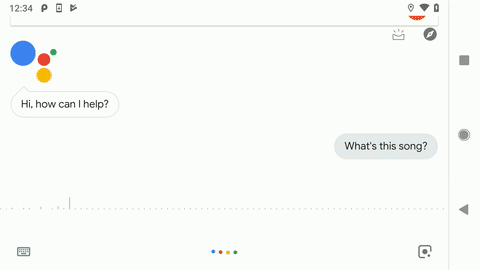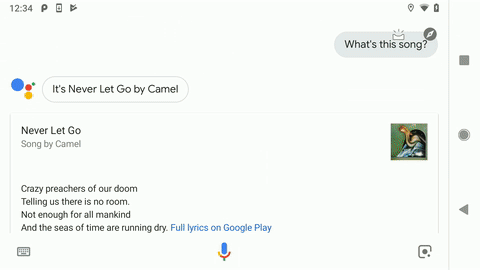
Recently, we introduced a new version of Sound Search that is powered by some of the same technology used by Now Playing. You can use it through the Google Search app or the Google Assistant on any Android phone. Just start a voice query, and if there’s music playing near you, a “What’s this song?” suggestion will pop up for you to press. Otherwise, you can just ask, “Hey Google, what’s this song?” With this latest version of Sound Search, you’ll get faster, more accurate results than ever before!
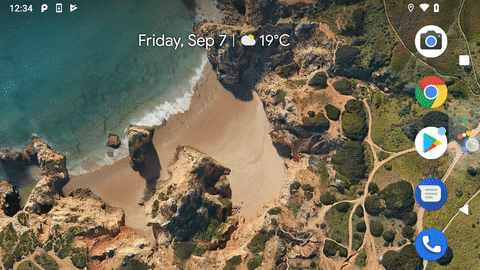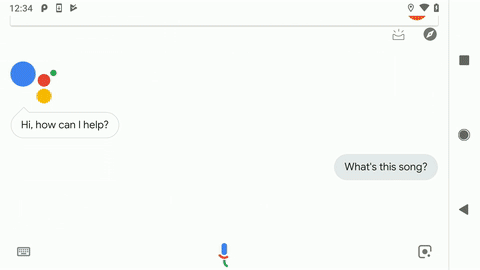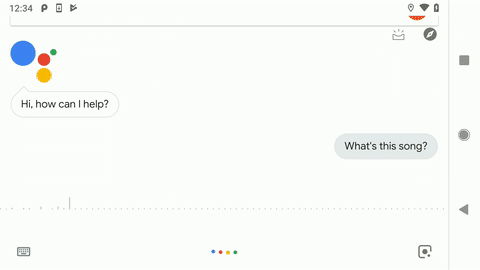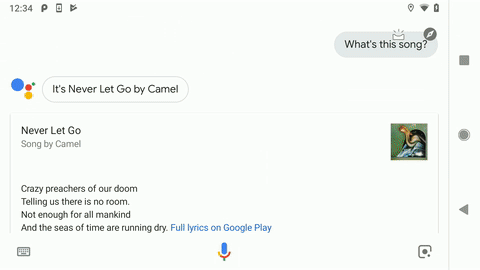
Now Playing versus Sound Search
Now Playing miniaturized music recognition technology such that it was small and efficient enough to be run continuously on a mobile device without noticeable battery impact. To do this we developed an entirely new system using convolutional neural networks to turn a few seconds of audio into a unique “fingerprint.” This fingerprint is then compared against an on-device database holding tens of thousands of songs, which is regularly updated to add newly released tracks and remove those that are no longer popular. In contrast, the server-side Sound Search system is very different, having to match against ~1000x as many songs as Now Playing. Making Sound Search both faster and more accurate with a substantially larger musical library presented several unique challenges. But before we go into that, a few details on how Now Playing works.
The Core Matching Process of Now Playing
Now Playing generates the musical “fingerprint” by projecting the musical features of an eight-second portion of audio into a sequence of low-dimensional embedding spaces consisting of seven two-second clips at 1 second intervals, giving a segmentation like this:

Now Playing then searches the on-device song database, which was generated by processing popular music with the same neural network, for similar embedding sequences. The database search uses a two phase algorithm to identify matching songs, where the first phase uses a fast but inaccurate algorithm which searches the whole song database to find a few likely candidates, and the second phase does a detailed analysis of each candidate to work out which song, if any, is the right one.
- Matching, phase 1: Finding good candidates: For every embedding, Now Playing performs a nearest neighbor search on the on-device database of songs for similar embeddings. The database uses a hybrid of spatial partitioning and vector quantization to efficiently search through millions of embedding vectors. Because the audio buffer is noisy, this search is approximate, and not every embedding will find a nearby match in the database for the correct song. However, over the whole clip, the chances of finding several nearby embeddings for the correct song are very high, so the search is narrowed to a small set of songs which got multiple hits.
- Matching, phase 2: Final matching: Because the database search used above is approximate, Now Playing may not find song embeddings which are nearby to some embeddings in our query. Therefore, in order to calculate an accurate similarity score, Now Playing retrieves all embeddings for each song in the database which might be relevant to fill in the “gaps”. Then, given the sequence of embeddings from the audio buffer and another sequence of embeddings from a song in the on-device database, Now Playing estimates their similarity pairwise and adds up the estimates to get the final matching score.
It’s critical to the accuracy of Now Playing to use a sequence of embeddings rather than a single embedding. The fingerprinting neural network is not accurate enough to allow identification of a song from a single embedding alone — each embedding will generate a lot of false positive results. However, combining the results from multiple embeddings allows the false positives to be easily removed, as the correct song will be a match to every embedding, while false positive matches will only be close to one or two embeddings from the input audio.
Scaling up Now Playing for the Sound Search server
So far, we’ve gone into some detail of how Now Playing matches songs to an on-device database. The biggest challenge in going from Now Playing, with tens of thousands of songs, to Sound Search, with tens of millions, is that there are a thousand times as many songs which could give a false positive result. To compensate for this without any other changes, we would have to increase the recognition threshold, which would mean needing more audio to get a confirmed match. However, the goal of the new Sound Search server was to be able to match faster, not slower, than Now Playing, so we didn’t want people to wait 10+ seconds for a result.
As Sound Search is a server-side system, it isn’t limited by processing and storage constraints in the same way Now Playing is. Therefore, we made two major changes to how we do fingerprinting, both of which increased accuracy at the expense of server resources:
- We quadrupled the size of the neural network used, and increased each embedding from 96 to 128 dimensions, which reduces the amount of work the neural network has to do to pack the high-dimensional input audio into a low-dimensional embedding. This is critical in improving the quality of phase two, which is very dependent on the accuracy of the raw neural network output.
- We doubled the density of our embeddings — it turns out that fingerprinting audio every 0.5s instead of every 1s doesn’t reduce the quality of the individual embeddings very much, and gives us a huge boost by doubling the number of embeddings we can use for the match.
We also decided to weight our index based on song popularity - in effect, for popular songs, we lower the matching threshold, and we raise it for obscure songs. Overall, this means that we can keep adding more (obscure) songs almost indefinitely to our database without slowing our recognition speed too much.
Conclusion
With Now Playing, we originally set out to use machine learning to create a robust audio fingerprint compact enough to run entirely on a phone. It turned out that we had, in fact, created a very good all-round audio fingerprinting system, and the ideas developed there carried over very well to the server-side Sound Search system, even though the challenges of Sound Search are quite different.
We still think there’s room for improvement though — we don’t always match when music is very quiet or in very noisy environments, and we believe we can make the system even faster. We are continuing to work on these challenges with the goal of providing the next generation in music recognition. We hope you’ll try it the next time you want to find out what song is playing! You can put a shortcut on your home screen like this:

Acknowledgements
We would like to thank Micha Riser, Mihajlo Velimirovic, Marvin Ritter, Ruiqi Guo, Sanjiv Kumar, Stephen Wu, Diego Melendo Casado, Katia Naliuka, Jason Sanders, Beat Gfeller, Julian Odell, Christian Frank, Dominik Roblek, Matt Sharifi and Blaise Aguera y Arcas.
Quick links
Other posts of interest
-

August 7, 2025
Achieving 10,000x training data reduction with high-fidelity labels- Human-Computer Interaction and Visualization ·
- Machine Intelligence ·
- Security, Privacy and Abuse Prevention
-

August 6, 2025
Insulin resistance prediction from wearables and routine blood biomarkers- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence
-

August 1, 2025
MLE-STAR: A state-of-the-art machine learning engineering agent- Machine Intelligence