Introducing AdaNet: Fast and Flexible AutoML with Learning Guarantees
October 30, 2018
Posted by Charles Weill, Software Engineer, Google AI, NYC
Quick links
Ensemble learning, the art of combining different machine learning (ML) model predictions, is widely used with neural networks to achieve state-of-the-art performance, benefitting from a rich history and theoretical guarantees to enable success at challenges such as the Netflix Prize and various Kaggle competitions. However, they aren’t used much in practice due to long training times, and the ML model candidate selection requires its own domain expertise. But as computational power and specialized deep learning hardware such as TPUs become more readily available, machine learning models will grow larger and ensembles will become more prominent. Now, imagine a tool that automatically searches over neural architectures, and learns to combine the best ones into a high-quality model.
Today, we’re excited to share AdaNet, a lightweight TensorFlow-based framework for automatically learning high-quality models with minimal expert intervention. AdaNet builds on our recent reinforcement learning and evolutionary-based AutoML efforts to be fast and flexible while providing learning guarantees. Importantly, AdaNet provides a general framework for not only learning a neural network architecture, but also for learning to ensemble to obtain even better models.
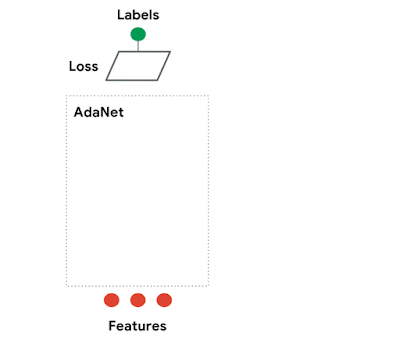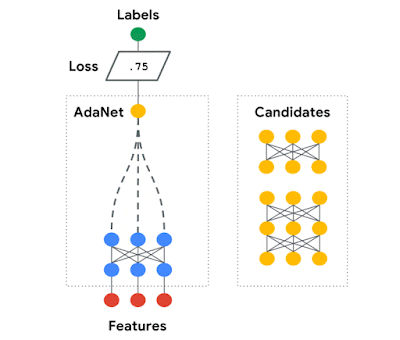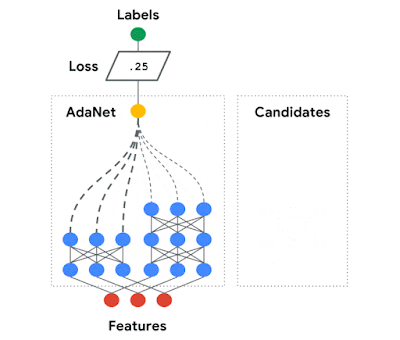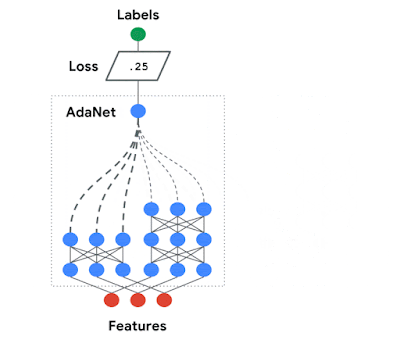
AdaNet is easy to use, and creates high-quality models, saving ML practitioners the time normally spent selecting optimal neural network architectures, implementing an adaptive algorithm for learning a neural architecture as an ensemble of subnetworks. AdaNet is capable of adding subnetworks of different depths and widths to create a diverse ensemble, and trade off performance improvement with the number of parameters.
 |
| AdaNet adaptively growing an ensemble of neural networks. At each iteration, it measures the ensemble loss for each candidate, and selects the best one to move onto the next iteration. |
AdaNet implements the TensorFlow Estimator interface, which greatly simplifies machine learning programming by encapsulating training, evaluation, prediction and export for serving. It integrates with open-source tools like TensorFlow Hub modules, TensorFlow Model Analysis, and Google Cloud’s Hyperparameter Tuner. Distributed training support significantly reduces training time, and scales linearly with available CPUs and accelerators (e.g. GPUs).
 |
| AdaNet’s accuracy (y-axis) per train step (x-axis) on CIFAR-100. The blue line is accuracy on the training set, and red line is performance on the test set. A new subnetwork begins training every million steps, and eventually improves the performance of the ensemble. The grey and green lines are the accuracies of the ensemble before adding the new subnetwork. |
Learning Guarantees
Building an ensemble of neural networks has several challenges: What are the best subnetwork architectures to consider? Is it best to reuse the same architectures or encourage diversity? While complex subnetworks with more parameters will tend to perform better on the training set, they may not generalize to unseen data due to their greater complexity. These challenges stem from evaluating model performance. We could evaluate performance on a hold-out set split from the training set, but in doing so would reduce the number of examples one can use for training the neural network.
Instead, AdaNet’s approach (presented in “AdaNet: Adaptive Structural Learning of Artificial Neural Networks” at ICML 2017) is to optimize an objective that balances the trade-offs between the ensemble’s performance on the training set and its ability to generalize to unseen data. The intuition is for the ensemble to include a candidate subnetwork only when it improves the ensemble’s training loss more than it affects its ability to generalize. This guarantees that:
- The generalization error of the ensemble is bounded by its training error and complexity.
- By optimizing this objective, we are directly minimizing this bound.
Extensible
We believe that the key to making a useful AutoML framework for both research and production use is to not only provide sensible defaults, but to also allow users to try their own subnetwork/model definitions. As a result, machine learning researchers, practitioners, and enthusiasts are invited to define their own AdaNet adanet.subnetwork.Builder using high level TensorFlow APIs like tf.layers.
Users who have already integrated a TensorFlow model in their system can easily convert their TensorFlow code into an AdaNet subnetwork, and use the adanet.Estimator to boost model performance while obtaining learning guarantees. AdaNet will explore their defined search space of candidate subnetworks and learn to ensemble the subnetworks. For instance, we took an open-source implementation of a NASNet-A CIFAR architecture, transformed it into a subnetwork, and improved upon CIFAR-10 state-of-the-art results after eight AdaNet iterations. Furthermore, our model achieves this result with fewer parameters:
 |
| Performance of a NASNet-A model as presented in Zoph et al., 2018 versus AdaNet learning to combine small NASNet-A subnetworks on CIFAR-10. |
Users can also fully define the search space of candidate subnetworks to explore by extending the adanet.subnetwork.Generator class. This allows them to grow or reduce their search space based on their available hardware. The search space of subnetworks can be as simple as duplicating the same subnetwork configuration with different random seeds, to training dozens of subnetworks with different hyperparameter combinations, and letting AdaNet choose the one to include in the final ensemble.
If you’re interested in trying AdaNet for yourself, please check out our Github repo, and walk through the tutorial notebooks. We’ve included a few working examples using dense layers and convolutions to get you started. AdaNet is an ongoing research project, and we welcome contributions. We’re excited to see how AdaNet can help the research community.
Acknowledgements
This project was only possible thanks to the members of the core team including Corinna Cortes, Mehryar Mohri, Xavi Gonzalvo, Charles Weill, Vitaly Kuznetsov, Scott Yak, and Hanna Mazzawi. We also extend a special thanks to our collaborators, residents and interns Gus Kristiansen, Galen Chuang, Ghassen Jerfel, Vladimir Macko, Ben Adlam, Scott Yang and the many others at Google who helped us test it out.
Quick links
Other posts of interest
-

November 13, 2025
Separating natural forests from other tree cover with AI for deforestation-free supply chains- Climate & Sustainability ·
- Global ·
- Open Source Models & Datasets ·
- Responsible AI
-

November 13, 2025
A new quantum toolkit for optimization- Algorithms & Theory ·
- Quantum
-

November 12, 2025
Differentially private machine learning at scale with JAX-Privacy- Algorithms & Theory ·
- Responsible AI ·
- Security, Privacy and Abuse Prevention