Fast and Easy Infinitely Wide Networks with Neural Tangents
March 13, 2020
Posted by Samuel S. Schoenholz, Senior Research Scientist and Roman Novak, Research Engineer, Google Research
The widespread success of deep learning across a range of domains such as natural language processing, conversational agents, and connectomics, has transformed the landscape of research in machine learning and left researchers with a number of interesting and important open questions such as: Why do deep neural networks (DNNs) generalize so well despite being overparameterized? What is the relationship between architecture, training, and performance for deep networks? How can one extract salient features from deep learning models?
One of the key theoretical insights that has allowed us to make progress in recent years has been that increasing the width of DNNs results in more regular behavior, and makes them easier to understand. A number of recent results have shown that DNNs that are allowed to become infinitely wide converge to another, simpler, class of models called Gaussian processes. In this limit, complicated phenomena (like Bayesian inference or gradient descent dynamics of a convolutional neural network) boil down to simple linear algebra equations. Insights from these infinitely wide networks frequently carry over to their finite counterparts. As such, infinite-width networks can be used as a lens to study deep learning, but also as useful models in their own right.
 |
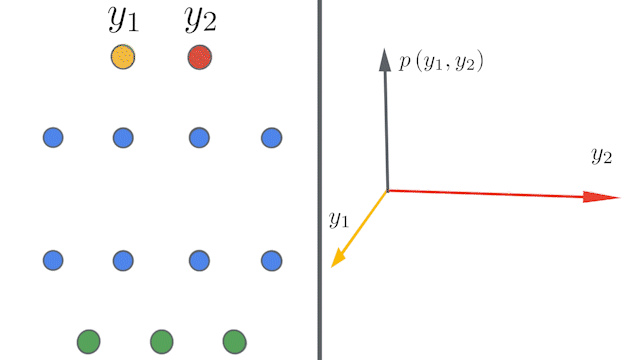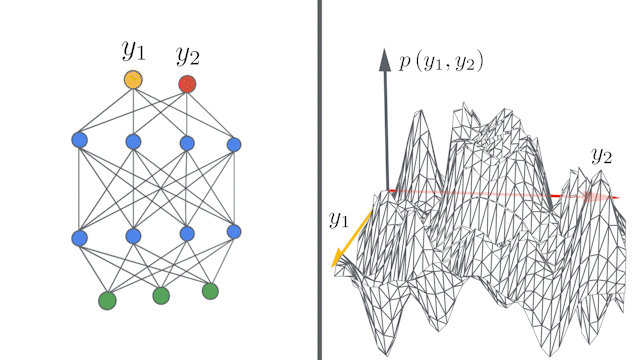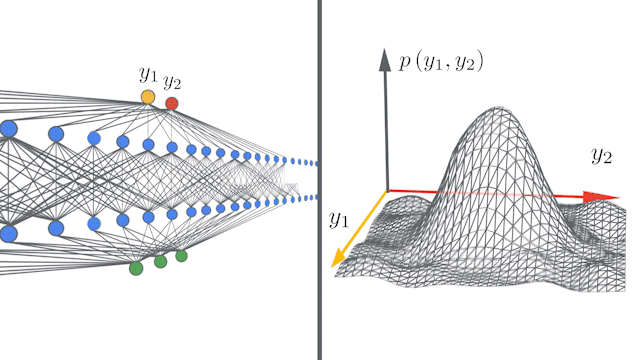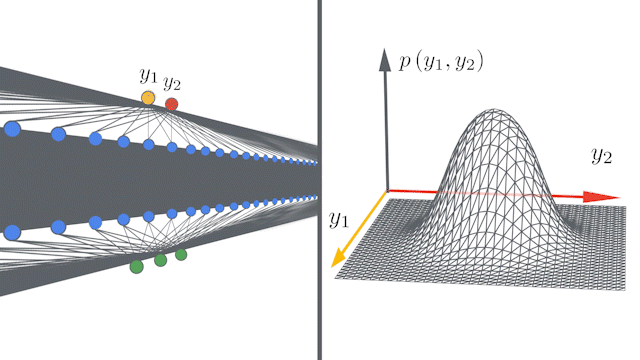
| Left: A schematic showing how deep neural networks induce simple input / output maps as they become infinitely wide. Right: As the width of a neural network increases , we see that the distribution of outputs over different random instantiations of the network becomes Gaussian. |
To address this issue and to accelerate theoretical progress in deep learning, we present Neural Tangents, a new open-source software library written in JAX that allows researchers to build and train infinitely wide neural networks as easily as finite neural networks. At its core, Neural Tangents provides an easy-to-use neural network library that builds finite- and infinite-width versions of neural networks simultaneously.
As an example of the utility of Neural Tangents, imagine training a fully-connected neural network on some data. Normally, a neural network is randomly initialized and then trained using gradient descent. Initializing and training many of these neural networks results in an ensemble. Often researchers and practitioners average the predictions from different members of the ensemble together for better performance. Additionally, the variance in the predictions of members of the ensemble can be used to estimate uncertainty. The downside is that training an ensemble of networks requires a significant computational budget, so it is often avoided. However, when the neural networks become infinitely wide, the ensemble is described by a Gaussian process with a mean and variance that can be computed throughout training.
With Neural Tangents, one can construct and train ensembles of these infinite-width networks at once using only five lines of code! The resulting training process is displayed below, and an interactive colaboratory notebook going through this experiment can be found here.
 |
| In both plots we compare training of an ensemble of finite neural networks with the infinite-width ensemble of the same architecture. The empirical mean and variance of the finite ensemble is displayed as a dashed black line between two dotted black lines. The closed-form mean and variance of the infinite-width ensemble is displayed as a solid colored line inside a filled color region. In both plots finite- and infinite-width ensembles match very closely and can be hard to distinguish. Left: Outputs (vertical f-axis) on the input data (horizontal x-axis) as the training progresses. Right: Train and test loss with uncertainty over the course of training. |
The above example shows the power of infinite-width neural networks to capture training dynamics. However, networks built using Neural Tangents can be applied to any problem on which you could apply a regular neural network. For example, below we compare three different infinite-width neural network architectures on image recognition using the CIFAR-10 dataset. Remarkably, we can evaluate ensembles of highly-elaborate models like infinitely wide residual networks in closed-form under both gradient descent and fully-Bayesian inference (an intractable task in the finite-width regime).

We invite everyone to explore the infinite-width versions of their models with Neural Tangents, and help us open the black box of deep learning. To get started, please check out the paper, the tutorial Colab notebook, and the Github repo — contributions, feature requests, and bug reports are very welcome. This work has been accepted as a spotlight at ICLR 2020.
Acknowledgements
Neural Tangents is being actively developed by Lechao Xiao, Roman Novak, Jiri Hron, Jaehoon Lee, Alex Alemi, Jascha Sohl-Dickstein, and Samuel S. Schoenholz. We also thank Yasaman Bahri and Greg Yang for the ongoing contributions to improve the library, as well as Sergey Ioffe, Ben Adlam, Ravid Ziv, and Jeffrey Pennington for frequent discussion and useful feedback. Finally, we thank Tom Small for creating the animation in the first figure.
Other posts of interest
-

April 12, 2024
Contrastive neural audio separation- Machine Intelligence ·
- Sound & Accoustics
-

April 11, 2024
Patchscopes: A unifying framework for inspecting hidden representations of language models- Machine Intelligence ·
- Natural Language Processing ·
- Responsible AI
-
March 28, 2024
AutoBNN: Probabilistic time series forecasting with compositional bayesian neural networks- Algorithms & Theory ·
- Machine Intelligence ·
- Open Source Models & Datasets