
Constructing Transformers For Longer Sequences with Sparse Attention Methods
March 25, 2021
Posted by Avinava Dubey, Research Scientist, Google Research
Natural language processing (NLP) models based on Transformers, such as BERT, RoBERTa, T5, or GPT3, are successful for a wide variety of tasks and a mainstay of modern NLP research. The versatility and robustness of Transformers are the primary drivers behind their wide-scale adoption, leading them to be easily adapted for a diverse range of sequence-based tasks — as a seq2seq model for translation, summarization, generation, and others, or as a standalone encoder for sentiment analysis, POS tagging, machine reading comprehension, etc. The key innovation in Transformers is the introduction of a self-attention mechanism, which computes similarity scores for all pairs of positions in an input sequence, and can be evaluated in parallel for each token of the input sequence, avoiding the sequential dependency of recurrent neural networks, and enabling Transformers to vastly outperform previous sequence models like LSTM.
A limitation of existing Transformer models and their derivatives, however, is that the full self-attention mechanism has computational and memory requirements that are quadratic with the input sequence length. With commonly available current hardware and model sizes, this typically limits the input sequence to roughly 512 tokens, and prevents Transformers from being directly applicable to tasks that require larger context, like question answering, document summarization or genome fragment classification. Two natural questions arise: 1) Can we achieve the empirical benefits of quadratic full Transformers using sparse models with computational and memory requirements that scale linearly with the input sequence length? 2) Is it possible to show theoretically that these linear Transformers preserve the expressivity and flexibility of the quadratic full Transformers?
We address both of these questions in a recent pair of papers. In “ETC: Encoding Long and Structured Inputs in Transformers”, presented at EMNLP 2020, we present the Extended Transformer Construction (ETC), which is a novel method for sparse attention, in which one uses structural information to limit the number of computed pairs of similarity scores. This reduces the quadratic dependency on input length to linear and yields strong empirical results in the NLP domain. Then, in “Big Bird: Transformers for Longer Sequences”, presented at NeurIPS 2020, we introduce another sparse attention method, called BigBird that extends ETC to more generic scenarios where prerequisite domain knowledge about structure present in the source data may be unavailable. Moreover, we also show that theoretically our proposed sparse attention mechanism preserves the expressivity and flexibility of the quadratic full Transformers. Our proposed methods achieve a new state of the art on challenging long-sequence tasks, including question answering, document summarization and genome fragment classification.
Attention as a Graph
The attention module used in Transformer models computes similarity scores for all pairs of positions in an input sequence. It is useful to think of the attention mechanism as a directed graph, with tokens represented by nodes and the similarity score computed between a pair of tokens represented by an edge. In this view, the full attention model is a complete graph. The core idea behind our approach is to carefully design sparse graphs, such that one only computes a linear number of similarity scores.
 |
| Full attention can be viewed as a complete graph. |
Extended Transformer Construction (ETC)
On NLP tasks that require long and structured inputs, we propose a structured sparse attention mechanism, which we call Extended Transformer Construction (ETC). To achieve structured sparsification of self attention, we developed the global-local attention mechanism. Here the input to the Transformer is split into two parts: a global input where tokens have unrestricted attention, and a long input where tokens can only attend to either the global input or to a local neighborhood. This achieves linear scaling of attention, which allows ETC to significantly scale input length.
In order to further exploit the structure of long documents, ETC combines additional ideas: representing the positional information of the tokens in a relative way, rather than using their absolute position in the sequence; using an additional training objective beyond the usual masked language model (MLM) used in models like BERT; and flexible masking of tokens to control which tokens can attend to which other tokens. For example, given a long selection of text, a global token is applied to each sentence, which connects to all tokens within the sentence, and a global token is also applied to each paragraph, which connects to all tokens within the same paragraph.
 |
| An example of document structure based sparse attention of ETC model. The global variables are denoted by C (in blue) for paragraph, S (yellow) for sentence while the local variables are denoted by X (grey) for tokens corresponding to the long input. |
With this approach, we report state-of-the-art results in five challenging NLP datasets requiring long or structured inputs: TriviaQA, Natural Questions (NQ), HotpotQA, WikiHop, and OpenKP.
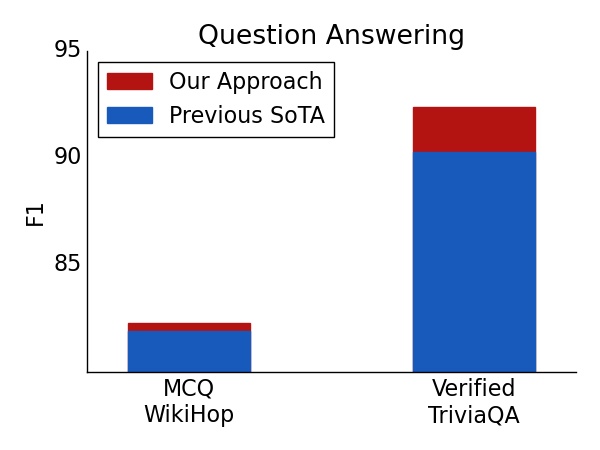 |
| Test set result on Question Answering. For both verified TriviaQA and WikiHop, using ETC achieved a new state of the art. |
BigBird
Extending the work of ETC, we propose BigBird — a sparse attention mechanism that is also linear in the number of tokens and is a generic replacement for the attention mechanism used in Transformers. In contrast to ETC, BigBird doesn’t require any prerequisite knowledge about structure present in the source data. Sparse attention in the BigBird model consists of three main parts:
- A set of global tokens attending to all parts of the input sequence
- All tokens attending to a set of local neighboring tokens
- All tokens attending to a set of random tokens
 |
| BigBird sparse attention can be seen as adding few global tokens on Watts-Strogatz graph. |
In the BigBird paper, we explain why sparse attention is sufficient to approximate quadratic attention, partially explaining why ETC was successful. A crucial observation is that there is an inherent tension between how few similarity scores one computes and the flow of information between different nodes (i.e., the ability of one token to influence each other). Global tokens serve as a conduit for information flow and we prove that sparse attention mechanisms with global tokens can be as powerful as the full attention model. In particular, we show that BigBird is as expressive as the original Transformer, is computationally universal (following the work of Yun et al. and Perez et al.), and is a universal approximator of continuous functions. Furthermore, our proof suggests that the use of random graphs can further help ease the flow of information — motivating the use of the random attention component.
This design scales to much longer sequence lengths for both structured and unstructured tasks. Further scaling can be achieved by using gradient checkpointing by trading off training time for sequence length. This lets us extend our efficient sparse transformers to include generative tasks that require an encoder and a decoder, such as long document summarization, on which we achieve a new state of the art.
 |
| Summarization ROUGE score for long documents. Both for BigPatent and ArXiv datasets, we achieve a new state of the art result. |
Moreover, the fact that BigBird is a generic replacement also allows it to be extended to new domains without pre-existing domain knowledge. In particular, we introduce a novel application of Transformer-based models where long contexts are beneficial — extracting contextual representations of genomic sequences (DNA). With longer masked language model pre-training, BigBird achieves state-of-the-art performance on downstream tasks, such as promoter-region prediction and chromatin profile prediction.
 |
| On multiple genomics tasks, such as promoter region prediction (PRP), chromatin-profile prediction including transcription factors (TF), histone-mark (HM) and DNase I hypersensitive (DHS) detection, we outperform baselines. Moreover our results show that Transformer models can be applied to multiple genomics tasks that are currently underexplored. |
Main Implementation Idea
One of the main impediments to the large scale adoption of sparse attention is the fact that sparse operations are quite inefficient in modern hardware. Behind both ETC and BigBird, one of our key innovations is to make an efficient implementation of the sparse attention mechanism. As modern hardware accelerators like GPUs and TPUs excel using coalesced memory operations, which load blocks of contiguous bytes at once, it is not efficient to have small sporadic look-ups caused by a sliding window (for local attention) or random element queries (random attention). Instead we transform the sparse local and random attention into dense tensor operations to take full advantage of modern single instruction, multiple data (SIMD) hardware.
To do this, we first “blockify” the attention mechanism to better leverage GPUs/TPUs, which are designed to operate on blocks. Then we convert the sparse attention mechanism computation into a dense tensor product through a series of simple matrix operations such as reshape, roll, and gather, as illustrated in the animation below.
 |
| Illustration of how sparse window attention is efficiently computed using roll and reshape, and without small sporadic look-ups. |
Recently, “Long Range Arena: A Benchmark for Efficient Transformers“ provided a benchmark of six tasks that require longer context, and performed experiments to benchmark all existing long range transformers. The results show that the BigBird model, unlike its counterparts, clearly reduces memory consumption without sacrificing performance.
Conclusion
We show that carefully designed sparse attention can be as expressive and flexible as the original full attention model. Along with theoretical guarantees, we provide a very efficient implementation which allows us to scale to much longer inputs. As a consequence, we achieve state-of-the-art results for question answering, document summarization and genome fragment classification. Given the generic nature of our sparse attention, the approach should be applicable to many other tasks like program synthesis and long form open domain question answering. We have open sourced the code for both ETC (github) and BigBird (github), both of which run efficiently for long sequences on both GPUs and TPUs.
Acknowledgements
This research resulted as a collaboration with Amr Ahmed, Joshua Ainslie, Chris Alberti, Vaclav Cvicek, Avinava Dubey, Zachary Fisher, Guru Guruganesh, Santiago Ontañón, Philip Pham, Anirudh Ravula, Sumit Sanghai, Qifan Wang, Li Yang, Manzil Zaheer, who co-authored EMNLP and NeurIPS papers.
Other posts of interest
-

April 12, 2024
Contrastive neural audio separation- Machine Intelligence ·
- Sound & Accoustics
-

April 11, 2024
Patchscopes: A unifying framework for inspecting hidden representations of language models- Machine Intelligence ·
- Natural Language Processing ·
- Responsible AI
-

April 10, 2024
SOAR: New algorithms for even faster vector search with ScaNN- Algorithms & Theory ·
- Conferences & Events ·
- Data Mining & Modeling