
Improving Vision Transformer Efficiency and Accuracy by Learning to Tokenize
December 7, 2021
Posted by Michael Ryoo, Research Scientist, Robotics at Google and Anurag Arnab, Research Scientist, Google Research
Transformer models consistently obtain state-of-the-art results in computer vision tasks, including object detection and video classification. In contrast to standard convolutional approaches that process images pixel-by-pixel, the Vision Transformers (ViT) treat an image as a sequence of patch tokens (i.e., a smaller part, or “patch”, of an image made up of multiple pixels). This means that at every layer, a ViT model recombines and processes patch tokens based on relations between each pair of tokens, using multi-head self-attention. In doing so, ViT models have the capability to construct a global representation of the entire image.
At the input-level, the tokens are formed by uniformly splitting the image into multiple segments, e.g., splitting an image that is 512 by 512 pixels into patches that are 16 by 16 pixels. At the intermediate levels, the outputs from the previous layer become the tokens for the next layer. In the case of videos, video ‘tubelets’ such as 16x16x2 video segments (16x16 images over 2 frames) become tokens. The quality and quantity of the visual tokens decide the overall quality of the Vision Transformer.
The main challenge in many Vision Transformer architectures is that they often require too many tokens to obtain reasonable results. Even with 16x16 patch tokenization, for instance, a single 512x512 image corresponds to 1024 tokens. For videos with multiple frames, that results in tens of thousands of tokens needing to be processed at every layer. Considering that the Transformer computation increases quadratically with the number of tokens, this can often make Transformers intractable for larger images and longer videos. This leads to the question: is it really necessary to process that many tokens at every layer?
In “TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?”, an earlier version of which is presented at NeurIPS 2021, we show that adaptively generating a smaller number of tokens, rather than always relying on tokens formed by uniform splitting, enables Vision Transformers to run much faster and perform better. TokenLearner is a learnable module that takes an image-like tensor (i.e., input) and generates a small set of tokens. This module could be placed at various different locations within the model of interest, significantly reducing the number of tokens to be handled in all subsequent layers. The experiments demonstrate that having TokenLearner saves memory and computation by half or more without damaging classification performance, and because of its ability to adapt to inputs, it even increases the accuracy.
The TokenLearner
We implement TokenLearner using a straightforward spatial attention approach. In order to generate each learned token, we compute a spatial attention map highlighting regions-of-importance (using convolutional layers or MLPs). Such a spatial attention map is then applied to the input to weight each region differently (and discard unnecessary regions), and the result is spatially pooled to generate the final learned tokens. This is repeated multiple times in parallel, resulting in a few (~10) tokens out of the original input. This can also be viewed as performing a soft-selection of the pixels based on the weight values, followed by global average pooling. Note that the functions to compute the attention maps are governed by different sets of learnable parameters, and are trained in an end-to-end fashion. This allows the attention functions to be optimized in capturing different spatial information in the input. The figure below illustrates the process.
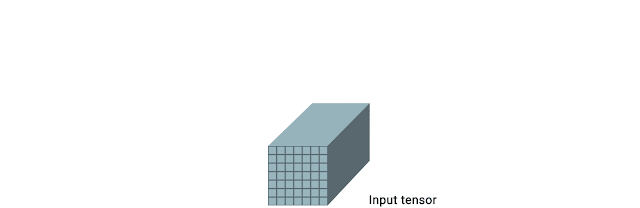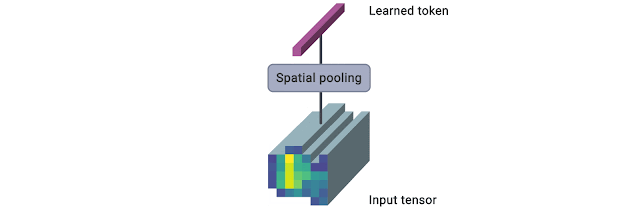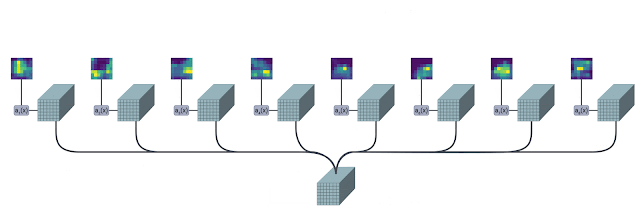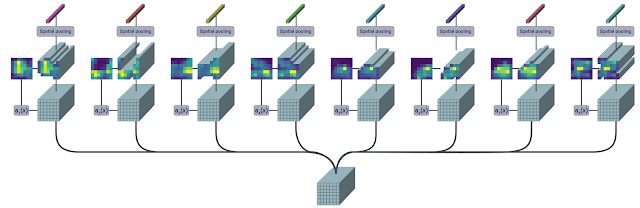 |
| The TokenLearner module learns to generate a spatial attention map for each output token, and uses it to abstract the input to tokenize. In practice, multiple spatial attention functions are learned, are applied to the input, and generate different token vectors in parallel. |
As a result, instead of processing fixed, uniformly tokenized inputs, TokenLearner enables models to process a smaller number of tokens that are relevant to the specific recognition task. That is, (1) we enable adaptive tokenization so that the tokens can be dynamically selected conditioned on the input, and (2) this effectively reduces the total number of tokens, greatly reducing the computation performed by the network. These dynamically and adaptively generated tokens can be used in standard transformer architectures such as ViT for images and ViViT for videos.
Where to Place TokenLearner
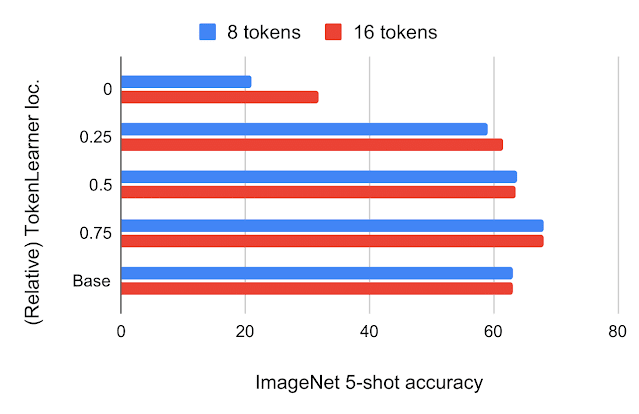
After building the TokenLearner module, we had to determine where to place it. We first tried placing it at different locations within the standard ViT architecture with 224x224 images. The number of tokens TokenLearner generated was 8 and 16, much less than 196 or 576 tokens the standard ViTs use. The below figure shows ImageNet few-shot classification accuracies and FLOPS of the models with TokenLearner inserted at various relative locations within ViT B/16, which is the base model with 12 attention layers operating on 16x16 patch tokens.
 |
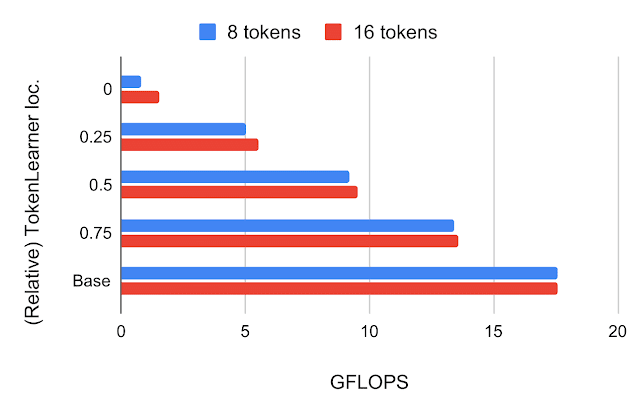 |
| Top: ImageNet 5-shot transfer accuracy with JFT 300M pre-training, with respect to the relative TokenLearner locations within ViT B/16. Location 0 means TokenLearner is placed before any Transformer layer. Base is the original ViT B/16. Bottom: Computation, measured in terms of billions of floating point operations (GFLOPS), per relative TokenLearner location. |
We found that inserting TokenLearner after the initial quarter of the network (at 1/4) achieves almost identical accuracies as the baseline, while reducing the computation to less than a third of the baseline. In addition, placing TokenLearner at the later layer (after 3/4 of the network) achieves even better performance compared to not using TokenLearner while performing faster, thanks to its adaptiveness. Due to the large difference between the number of tokens before and after TokenLearner (e.g., 196 before and 8 after), the relative computation of the transformers after the TokenLearner module becomes almost negligible.
Comparing Against ViTs
We compared the standard ViT models with TokenLearner against those without it while following the same setting on ImageNet few-shot transfer. TokenLearner was placed in the middle of each ViT model at various locations such as at 1/2 and at 3/4. The below figure shows the performance/computation trade-off of the models with and without TokenLearner.
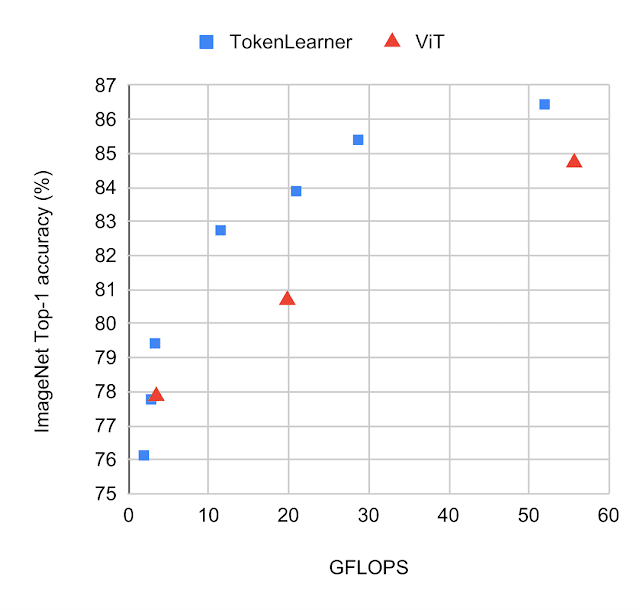 |
| Performance of various versions of ViT models with and without TokenLearner, on ImageNet classification. The models were pre-trained with JFT 300M. The closer a model is to the top-left of each graph the better, meaning that it runs faster and performs better. Observe how TokenLearner models perform better than ViT in terms of both accuracy and computation. |
We also inserted TokenLearner within larger ViT models, and compared them against the giant ViT G/14 model. Here, we applied TokenLearner to ViT L/10 and L/8, which are the ViT models with 24 attention layers taking 10x10 (or 8x8) patches as initial tokens. The below figure shows that despite using many fewer parameters and less computation, TokenLearner performs comparably to the giant G/14 model with 48 layers.
 |
 |
| Left: Classification accuracy of large-scale TokenLearner models compared to ViT G/14 on ImageNet datasets. Right: Comparison of the number of parameters and FLOPS. |
High-Performing Video Models
Video understanding is one of the key challenges in computer vision, so we evaluated TokenLearner on multiple video classification datasets. This was done by adding TokenLearner into Video Vision Transformers (ViViT), which can be thought of as a spatio-temporal version of ViT. TokenLearner learned 8 (or 16) tokens per timestep.
When combined with ViViT, TokenLearner obtains state-of-the-art (SOTA) performance on multiple popular video benchmarks, including Kinetics-400, Kinetics-600, Charades, and AViD, outperforming the previous Transformer models on Kinetics-400 and Kinetics-600 as well as previous CNN models on Charades and AViD.
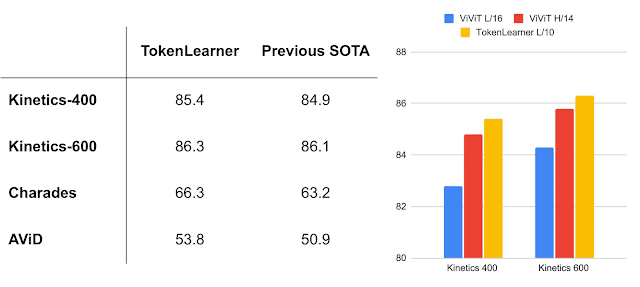 |
| Models with TokenLearner outperform state-of-the-art on popular video benchmarks (captured from Nov. 2021). Left: popular video classification tasks. Right: comparison to ViViT models. |
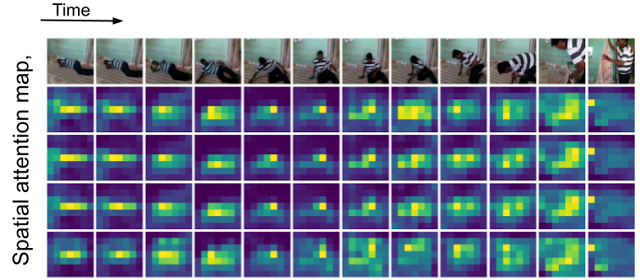 |
| Visualization of the spatial attention maps in TokenLearner, over time. As the person is moving in the scene, TokenLearner pays attention to different spatial locations to tokenize. |
Conclusion
While Vision Transformers serve as powerful models for computer vision, a large number of tokens and their associated computation amount have been a bottleneck for their application to larger images and longer videos. In this project, we illustrate that retaining such a large number of tokens and fully processing them over the entire set of layers is not necessary. Further, we demonstrate that by learning a module that extracts tokens adaptively based on the input image allows attaining even better performance while saving compute. The proposed TokenLearner was particularly effective in video representation learning tasks, which we confirmed with multiple public datasets. A preprint of our work as well as code are publicly available.
Acknowledgement
We thank our co-authors: AJ Piergiovanni, Mostafa Dehghani, and Anelia Angelova. We also thank the Robotics at Google team members for the motivating discussions.
Other posts of interest
-

April 17, 2024
Robust speech recognition in AR through infinite virtual rooms with acoustic modeling- Human-Computer Interaction and Visualization ·
- Machine Perception ·
- Speech Processing
-

April 12, 2024
Contrastive neural audio separation- Machine Intelligence ·
- Sound & Accoustics
-

April 11, 2024
Patchscopes: A unifying framework for inspecting hidden representations of language models- Machine Intelligence ·
- Natural Language Processing ·
- Responsible AI