
Distributing the Edit History of Wikipedia Infoboxes
May 30, 2013
Posted by Enrique Alfonseca, Google Research
Aside from its value as a general-purpose encyclopedia, Wikipedia is also one of the most widely used resources to acquire, either automatically or semi-automatically, knowledge bases of structured data. Much research has been devoted to automatically building disambiguation resources, parallel corpora and structured knowledge from Wikipedia. Still, most of those projects have been based on single snapshots of Wikipedia, extracting the attribute values that were valid at a particular point in time. So about a year ago we compiled and released a data set that allows researchers to see how data attributes can change over time.
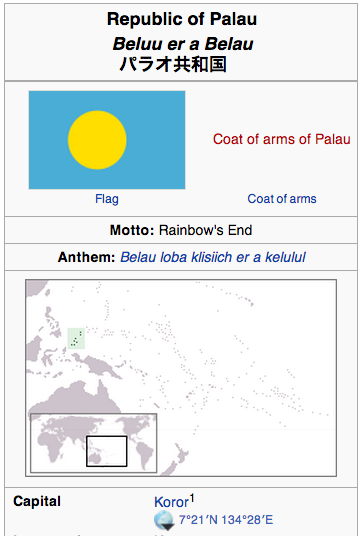
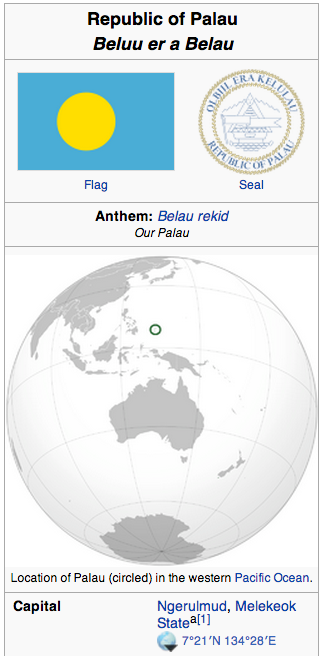
Figure 1. Infobox for the Republic of Palau in 2006 and 2013 showing the capital change.
Many attributes vary over time. These include the presidents of countries, the spouses of people, the populations of cities and the number of employees of companies. Every Wikipedia page has an associated history from which the users can view and compare past versions. Having the historical values of Infobox entries available would provide a historical overview of change affecting each entry, to understand which attributes are more likely to change over time or have a regularity in their changes, and which ones attract more user interest and are actually updated in a timely fashion. We believe that such a resource will also be useful in training systems to learn to extract data from documents, as it will allow us to collect more training examples by matching old values of an attribute inside old pages.
For this reason, we released, in collaboration with Wikimedia Deutschland e.V., a resource containing all the edit history of infoboxes in Wikipedia pages. While this was already available indirectly in Wikimedia’s full history dumps, the smaller size of the released dataset will make it easier to download and process this data. The released dataset contains 38,979,871 infobox attribute updates for 1,845,172 different entities, and it is available for download. A description of the dataset can be found in our paper WHAD: Wikipedia Historical Attributes Data, accepted for publication at the Language Resources and Evaluation journal.
What kind of information can be learned from this data? Some examples from preliminary analyses include the following:
- Every country in the world has a population in its Wikipedia attribute, which is updated at least yearly for more than 90% of them. The average error rate with respect to the yearly World Bank estimates is between two and three percent, mostly due to rounding.
- 50% of deaths are updated into Wikipedia infoboxes within a couple of days... but for scientists it takes 31 days to reach 50% coverage!
- For the last episode of TV shows, the airing date is updated for 50% of them within 9 days; for for the first episode of TV shows, it takes 106 days.
Thanks to Googler Jean-Yves Delort and Guillermo Garrido and Anselmo Peñas from UNED for putting this dataset together, and to Angelika Mühlbauer and Kai Nissen from Wikipedia Deutschland for their support. Thanks also to Thomas Hofmann and Fernando Pereira for making this data release possible.
-
Labels:
- Natural Language Processing
Other posts of interest
-

April 11, 2024
Patchscopes: A unifying framework for inspecting hidden representations of language models- Machine Intelligence ·
- Natural Language Processing ·
- Responsible AI
-
March 14, 2024
Cappy: Outperforming and boosting large multi-task language models with a small scorer- Machine Intelligence ·
- Machine Perception ·
- Natural Language Processing
-
March 11, 2024
Chain-of-table: Evolving tables in the reasoning chain for table understanding- Machine Intelligence ·
- Natural Language Processing