Introducing Semantic Experiences with Talk to Books and Semantris
April 13, 2018
Posted by Ray Kurzweil, Director of Engineering and Rachel Bernstein, Product Manager, Google Research
Natural language understanding has evolved substantially in the past few years, in part due to the development of word vectors that enable algorithms to learn about the relationships between words, based on examples of actual language usage. These vector models map semantically similar phrases to nearby points based on equivalence, similarity or relatedness of ideas and language. Last year, we used hierarchical vector models of language to make improvements to Smart Reply for Gmail. More recently, we’ve been exploring other applications of these methods.
Today, we are proud to share Semantic Experiences, a website showing two examples of how these new capabilities can drive applications that weren’t possible before. Talk to Books is an entirely new way to explore books by starting at the sentence level, rather than the author or topic level. Semantris is a word association game powered by machine learning, where you type out words associated with a given prompt. We have also published “Universal Sentence Encoder”, which describes the models used for these examples in more detail. Lastly, we’ve provided a pretrained semantic TensorFlow module for the community to experiment with their own sentence and phrase encoding.
Modeling approach
Our approach extends the idea of representing language in a vector space by creating vectors for larger chunks of language such as full sentences and small paragraphs. Since language is composed of hierarchies of concepts, we create the vectors using a hierarchy of modules, each of which considers features that correspond to sequences at different temporal scales. Relatedness, synonymy, antonymy, meronymy, holonymy, and many other types of relationships may all be represented in vector space language models if we train them in the right way and then pose the right “questions”. We describe this method in our paper, “Efficient Natural Language Response for Smart Reply.”
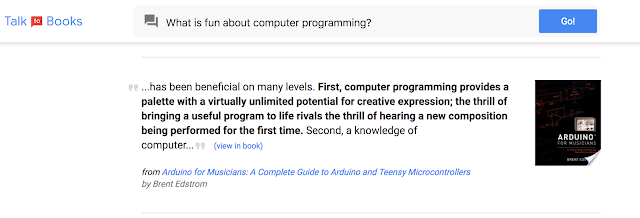
Talk to Books
With Talk to Books, we provide an entirely new way to explore books. You make a statement or ask a question, and the tool finds sentences in books that respond, with no dependence on keyword matching. In a sense you are talking to the books, getting responses which can help you determine if you’re interested in reading them or not.
 |
| Talk to Books |
This capability is unique and can help you find interesting books that a keyword search might not surface, but there’s still room for improvement. For example, this experiment works at the sentence level (rather than at the paragraph level, as in Smart Reply for Gmail) so a “good” matching sentence can still be taken out of context. You might find books and passages that you didn’t expect, or the reason a particular passage was highlighted might not be obvious. You may also notice that being well-known does not make a book sort to the top; this experiment looks only at how well the individual sentences match up. However, one benefit of this is that the tool may help people discover unexpected authors and titles, and surface books in a way that is fresh and innovative.
Semantris
We are also providing Semantris, a word association game that is powered by this technology. When you enter a word or phrase, the game ranks all of the words on-screen, scoring them based on how well they respond to what you typed. Again, similarity, opposites and neighboring concepts are all fair-game using this semantic model. Try it out yourself to see what we mean! The time pressure in the Arcade version (shown below) will tempt you to enter in single words as prompts. The Blocks version has no time pressure, which makes it a great place to try out entering in phrases and sentences. You may enjoy exploring how obscure you can be with your hints.
 |
| Semantris Arcade |
Acknowledgements
Talk to Books was developed by Aaron Phillips, Amin Ahmad, Rachel Bernstein, Aaron Cohen, Noah Constant, Ray Kurzweil, Igor Krivokon, Vladimir Magay, Peter McKenzie, Bryan Richter, Chris Tar, Dave Uthus, and Ni Yan. Semantris was developed by Ben Pietrzak, RJ Mical, Steve Pucci, Maria Voitovich, Mo Adeleye, Diana Huang, Catherine McCurry, Tomomi Sohn, and Connor Moore. Core semantic search technology development was led by Brian Strope and Yunhsuan Sung. Fast scalable matching work was led by Sanjiv Kumar, Dave Dopson, and David Simcha. We'd also like to acknowledge Hallie Benjamin, Eric Breck, Mario Guajardo-Céspedes, Yoni Halpern, Margaret Mitchell, Ben Packer, Andrew Smart and Lucy Vasserman.
Other posts of interest
-

April 23, 2024
Safely repairing broken builds with ML- Machine Intelligence ·
- Software Systems & Engineering
-

April 12, 2024
Contrastive neural audio separation- Machine Intelligence ·
- Sound & Accoustics
-

April 11, 2024
Patchscopes: A unifying framework for inspecting hidden representations of language models- Machine Intelligence ·
- Natural Language Processing ·
- Responsible AI