Advancing Semi-supervised Learning with Unsupervised Data Augmentation
July 11, 2019
Posted by Qizhe Xie, Student Researcher and Thang Luong, Senior Research Scientist, Google Research, Brain Team
Success in deep learning has largely been enabled by key factors such as algorithmic advancements, parallel processing hardware (GPU / TPU), and the availability of large-scale labeled datasets, like ImageNet. However, when labeled data is scarce, it can be difficult to train neural networks to perform well. In this case, one can apply data augmentation methods, e.g., paraphrasing a sentence or rotating an image, to effectively increase the amount of labeled training data. Recently, there has been significant progress in the design of data augmentation approaches for a variety of areas such as natural language processing (NLP), vision, and speech. Unfortunately, data augmentation is often limited to supervised learning only, in which labels are required to transfer from original examples to augmented ones.
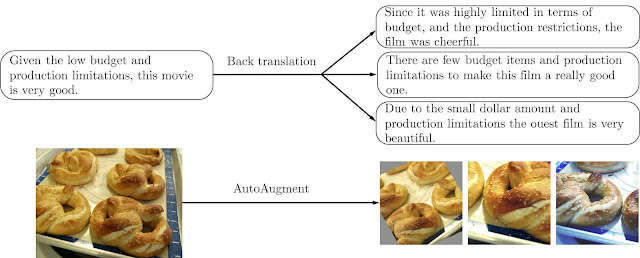
 |
| Example augmentation operations for text-based (top) or image-based (bottom) training data. |
Unsupervised Data Augmentation Explained
Unsupervised Data Augmentation (UDA) makes use of both labeled data and unlabeled data. To use labeled data, it computes the loss function using standard methods for supervised learning to train the model, as shown in the left part of the graph below. For unlabeled data, consistency training is applied to enforce the predictions to be similar for an unlabeled example and the augmented unlabeled example, as shown in the right part of the graph. Here, the same model is applied to both the unlabeled example and its augmented counterpart to produce two model predictions, from which a consistency loss is computed (i.e., the distance between the two prediction distributions). UDA then computes the final loss by jointly optimizing both the supervised loss from the labeled data and the unsupervised consistency loss from the unlabeled data.
 |
| An overview of Unsupervised Data Augmentation (UDA). Left: Standard supervised loss is computed when labeled data is available. Right: With unlabeled data, a consistency loss is computed between an example and its augmented version. |
Benchmarks in NLP and Computer Vision
UDA is surprisingly effective in the low-data regime. With only 20 labeled examples, UDA achieves an error rate of 4.20 on the IMDb sentiment analysis task by leveraging 50,000 unlabeled examples. This result outperforms the previous state-of-the-art model trained on 25,000 labeled examples with an error rate of 4.32. In the large-data regime, with the full training set, UDA also provides robust gains.
 |
| Benchmark on IMDb, a sentiment analysis task. UDA surpasses state-of-the-art results in supervised learning across different training sizes. |
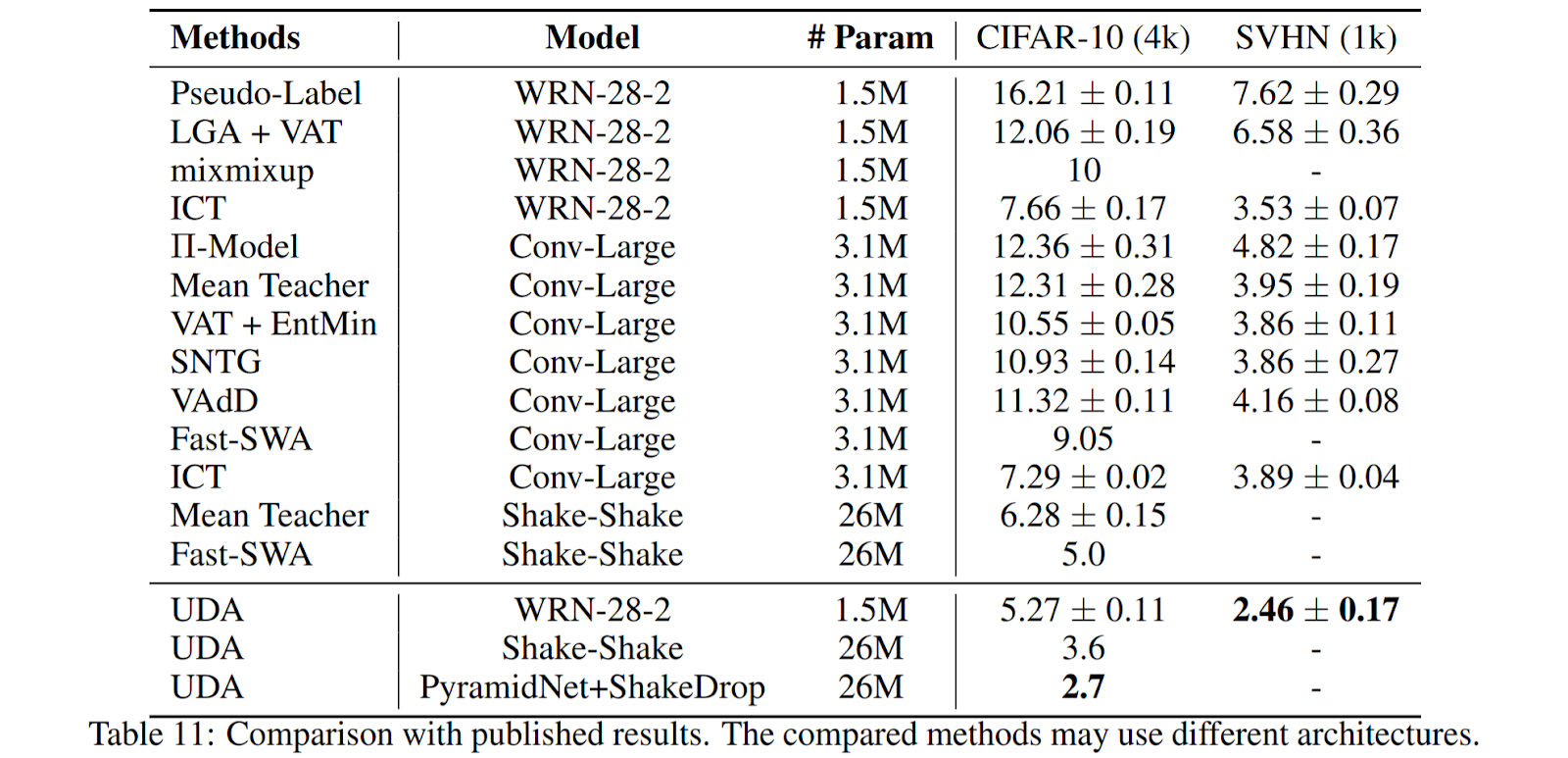 |
| SSL benchmark on CIFAR-10 and SVHN image classification tasks. UDA surpases existing semi-supervised learning methods. |
Release
We have released the codebase of UDA, together with all data augmentation methods, e.g., back-translation with pre-trained translation models, to replicate our results. We hope that this release will further advance the progress in semi-supervised learning.
Acknowledgements
Special thanks to the co-authors of the paper Zihang Dai, Eduard Hovy, and Quoc V. Le. We’d also like to thank Hieu Pham, Adams Wei Yu, Zhilin Yang, Colin Raffel, Olga Wichrowska, Ekin Dogus Cubuk, Guokun Lai, Jiateng Xie, Yulun Du, Trieu Trinh, Ran Zhao, Ola Spyra, Brandon Yang, Daiyi Peng, Andrew Dai, Samy Bengio and Jeff Dean for their help with this project. A preprint is available online.
In addition, we would also like to refer readers to other approaches on semi-supervised learning concurrently developed by our colleagues in Google Research, such as MixMatch and S4L, that have demonstrated promising results. We thank the authors of the MixMatch and S4L papers for their comments and feedback on our paper and blog post.
Other posts of interest
-

April 17, 2024
Robust speech recognition in AR through infinite virtual rooms with acoustic modeling- Human-Computer Interaction and Visualization ·
- Machine Perception ·
- Speech Processing
-

April 12, 2024
Contrastive neural audio separation- Machine Intelligence ·
- Sound & Accoustics
-

April 11, 2024
Patchscopes: A unifying framework for inspecting hidden representations of language models- Machine Intelligence ·
- Natural Language Processing ·
- Responsible AI