Multilingual Universal Sentence Encoder for Semantic Retrieval
July 12, 2019
Posted by Yinfei Yang and Amin Ahmad, Software Engineers, Google Research
Since it was introduced last year, “Universal Sentence Encoder (USE) for English’’ has become one of the most downloaded pre-trained text modules in Tensorflow Hub, providing versatile sentence embedding models that convert sentences into vector representations. These vectors capture rich semantic information that can be used to train classifiers for a broad range of downstream tasks. For example, a strong sentiment classifier can be trained from as few as one hundred labeled examples, and still be used to measure semantic similarity and for meaning-based clustering.
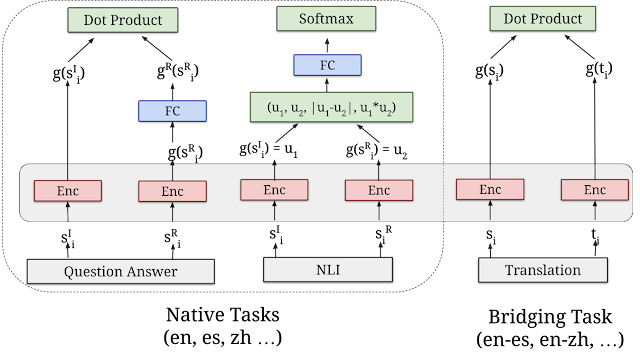
Today, we are pleased to announce the release of three new USE multilingual modules with additional features and potential applications. The first two modules provide multilingual models for retrieving semantically similar text, one optimized for retrieval performance and the other for speed and less memory usage. The third model is specialized for question-answer retrieval in sixteen languages (USE-QA), and represents an entirely new application of USE. All three multilingual modules are trained using a multi-task dual-encoder framework, similar to the original USE model for English, while using techniques we developed for improving the dual-encoder with additive margin softmax approach. They are designed not only to maintain good transfer learning performance, but to perform well on semantic retrieval tasks.
 |
| Multi-task training structure of the Universal Sentence Encoder. A variety of tasks and task structures are joined by shared encoder layers/parameters (pink boxes). |
The three new modules are all built on semantic retrieval architectures, which typically split the encoding of questions and answers into separate neural networks, which makes it possible to search among billions of potential answers within milliseconds. The key to using dual encoders for efficient semantic retrieval is to pre-encode all candidate answers to expected input queries and store them in a vector database that is optimized for solving the nearest neighbor problem, which allows a large number of candidates to be searched quickly with good precision and recall. For all three modules, the input query is then encoded into a vector on which we can perform an approximate nearest neighbor search. Together, this enables good results to be found quickly without needing to do a direct query/candidate comparison for every candidate. The prototypical pipeline is illustrated below:
 |
| A prototypical semantic retrieval pipeline, used for textual similarity. |
For semantic similarity tasks, the query and candidates are encoded using the same neural network. Two common semantic retrieval tasks made possible by the new modules include Multilingual Semantic Textual Similarity Retrieval and Multilingual Translation Pair Retrieval.
- Multilingual Semantic Textual Similarity Retrieval
Most existing approaches for finding semantically similar text require being given a pair of texts to compare. However, using the Universal Sentence Encoder, semantically similar text can be extracted directly from a very large database. For example, in an application like FAQ search, a system can first index all possible questions with associated answers. Then, given a user’s question, the system can search for known questions that are semantically similar enough to provide an answer. A similar approach was used to find comparable sentences from 50 million sentences in wikipedia. With the new multilingual USE models, this can be done in any of supported non-English languages.
- Multilingual Translation Pair Retrieval
The newly released modules can also be used to mine translation pairs to train neural machine translation systems. Given a source sentence in one language (“How do I get to the restroom?”), they can find the potential translation target in any other supported language (“¿Cómo llego al baño?”).
USE for Question-Answer Retrieval
The USE-QA module extends the USE architecture to question-answer retrieval applications, which generally take an input query and find relevant answers from a large set of documents that may be indexed at the document, paragraph, or even sentence level. The input query is encoded with the question encoding network, while the candidates are encoded with the answer encoding network.
 |
| Visualizing the action of a neural answer retrieval system. The blue point at the north pole represents the question vector. The other points represent the embeddings of various answers. The correct answer, highlighted here in red, is “closest” to the question, in that it minimizes the angular distance. The points in this diagram are produced by an actual USE-QA model, however, they have been projected downwards from ℝ500 to ℝ3 to assist the reader’s visualization. |
For Researchers and Developers
We're pleased to share the latest additions to the Universal Sentence Encoder family with the research community, and are excited to see what other applications will be found. These modules can be used as-is, or fine tuned using domain-specific data. Lastly, we will also host the semantic similarity for natural language page on Cloud AI Workshop to further encourage research in this area.
Acknowledgements
Mandy Guo, Daniel Cer, Noah Constant, Jax Law, Muthuraman Chidambaram for core modeling, Gustavo Hernandez Abrego, Chen Chen, Mario Guajardo-Cespedes for infrastructure and colabs, Steve Yuan, Chris Tar, Yunhsuan Sung, Brian Strope, Ray Kurzweil for discussion of the model architecture.
-
Labels:
- Natural Language Processing
Other posts of interest
-

April 11, 2024
Patchscopes: A unifying framework for inspecting hidden representations of language models- Machine Intelligence ·
- Natural Language Processing ·
- Responsible AI
-
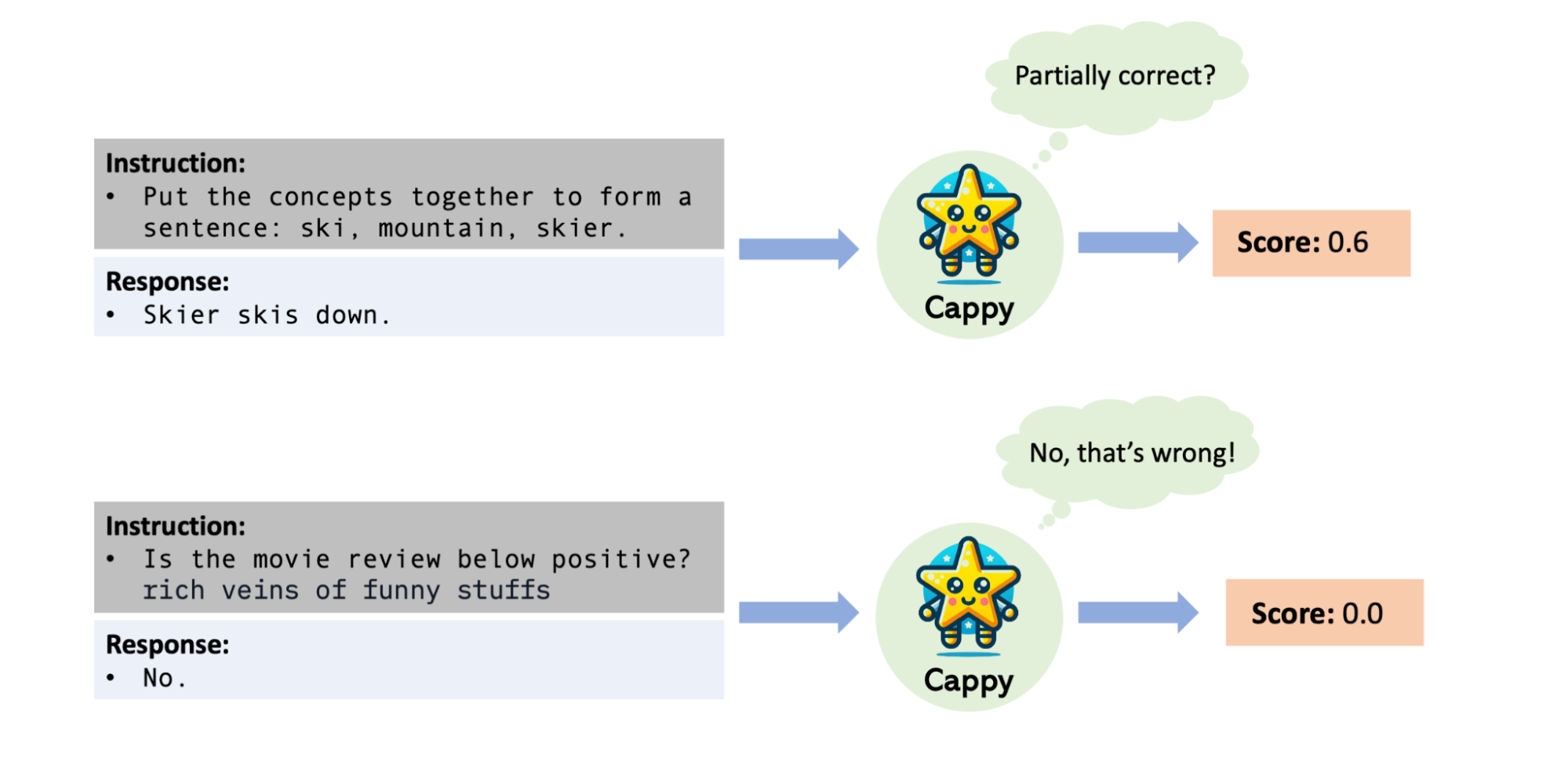
March 14, 2024
Cappy: Outperforming and boosting large multi-task language models with a small scorer- Machine Intelligence ·
- Machine Perception ·
- Natural Language Processing
-
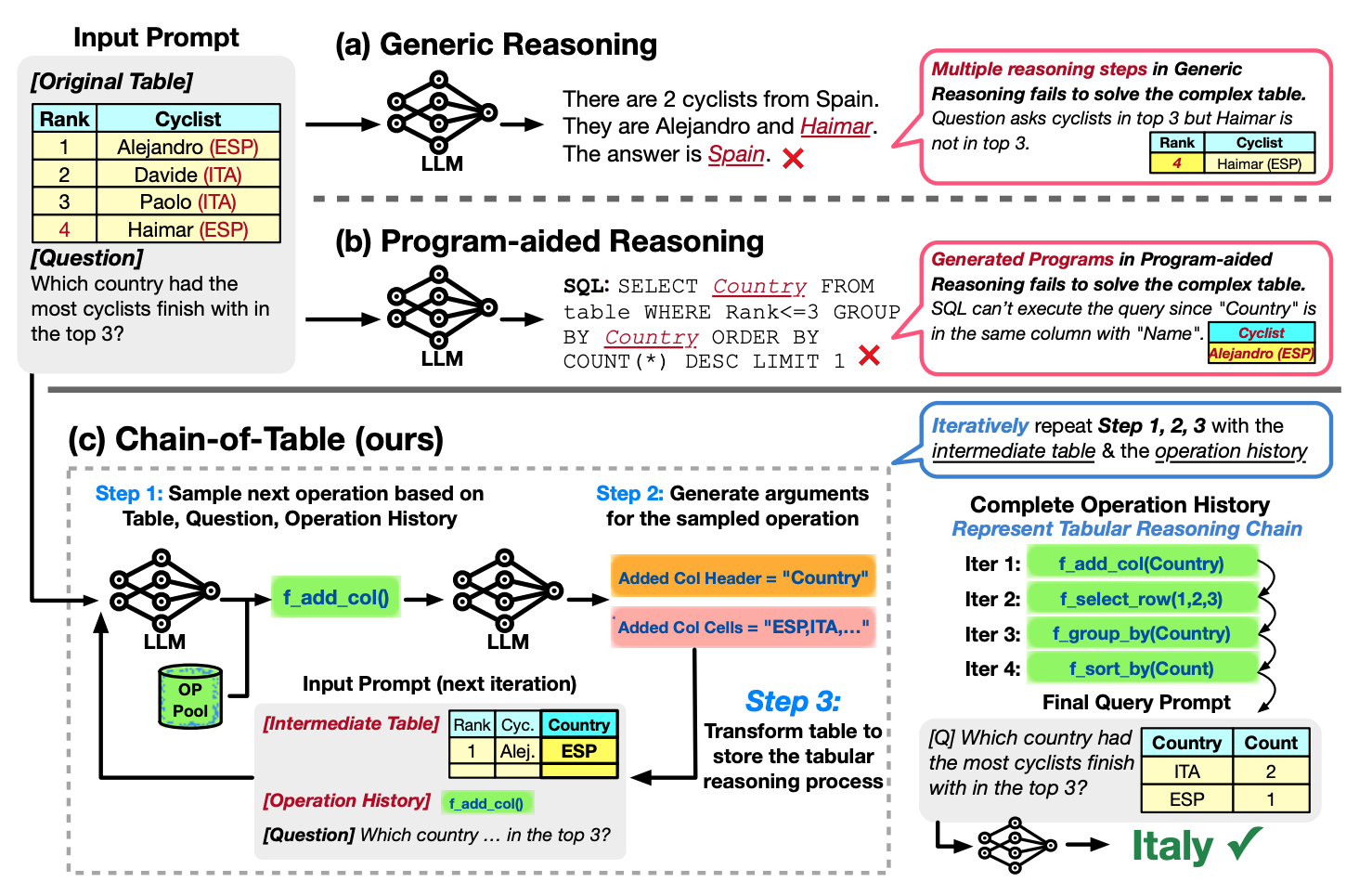
March 11, 2024
Chain-of-table: Evolving tables in the reasoning chain for table understanding- Machine Intelligence ·
- Natural Language Processing