
Exploring Transfer Learning with T5: the Text-To-Text Transfer Transformer
February 24, 2020
Posted by Adam Roberts, Staff Software Engineer and Colin Raffel, Senior Research Scientist, Google Research
Over the past few years, transfer learning has led to a new wave of state-of-the-art results in natural language processing (NLP). Transfer learning's effectiveness comes from pre-training a model on abundantly-available unlabeled text data with a self-supervised task, such as language modeling or filling in missing words. After that, the model can be fine-tuned on smaller labeled datasets, often resulting in (far) better performance than training on the labeled data alone. The recent success of transfer learning was ignited in 2018 by GPT, ULMFiT, ELMo, and BERT, and 2019 saw the development of a huge diversity of new methods like XLNet, RoBERTa, ALBERT, Reformer, and MT-DNN. The rate of progress in the field has made it difficult to evaluate which improvements are most meaningful and how effective they are when combined.
In “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer”, we present a large-scale empirical survey to determine which transfer learning techniques work best and apply these insights at scale to create a new model that we call the Text-To-Text Transfer Transformer (T5). We also introduce a new open-source pre-training dataset, called the Colossal Clean Crawled Corpus (C4). The T5 model, pre-trained on C4, achieves state-of-the-art results on many NLP benchmarks while being flexible enough to be fine-tuned to a variety of important downstream tasks. In order for our results to be extended and reproduced, we provide the code and pre-trained models, along with an easy-to-use Colab Notebook to help get started.
A Shared Text-To-Text Framework
With T5, we propose reframing all NLP tasks into a unified text-to-text-format where the input and output are always text strings, in contrast to BERT-style models that can only output either a class label or a span of the input. Our text-to-text framework allows us to use the same model, loss function, and hyperparameters on any NLP task, including machine translation, document summarization, question answering, and classification tasks (e.g., sentiment analysis). We can even apply T5 to regression tasks by training it to predict the string representation of a number instead of the number itself.
 |
| Diagram of our text-to-text framework. Every task we consider uses text as input to the model, which is trained to generate some target text. This allows us to use the same model, loss function, and hyperparameters across our diverse set of tasks including translation (green), linguistic acceptability (red), sentence similarity (yellow), and document summarization (blue). It also provides a standard testbed for the methods included in our empirical survey. |
A Large Pre-training Dataset (C4)
An important ingredient for transfer learning is the unlabeled dataset used for pre-training. To accurately measure the effect of scaling up the amount of pre-training, one needs a dataset that is not only high quality and diverse, but also massive. Existing pre-training datasets don’t meet all three of these criteria — for example, text from Wikipedia is high quality, but uniform in style and relatively small for our purposes, while the Common Crawl web scrapes are enormous and highly diverse, but fairly low quality.
To satisfy these requirements, we developed the Colossal Clean Crawled Corpus (C4), a cleaned version of Common Crawl that is two orders of magnitude larger than Wikipedia. Our cleaning process involved deduplication, discarding incomplete sentences, and removing offensive or noisy content. This filtering led to better results on downstream tasks, while the additional size allowed the model size to increase without overfitting during pre-training. C4 is available through TensorFlow Datasets.
A Systematic Study of Transfer Learning Methodology
With the T5 text-to-text framework and the new pre-training dataset (C4), we surveyed the vast landscape of ideas and methods introduced for NLP transfer learning over the past few years. The full details of the investigation can be found in our paper, including experiments on:
- model architectures, where we found that encoder-decoder models generally outperformed "decoder-only" language models;
- pre-training objectives, where we confirmed that fill-in-the-blank-style denoising objectives (where the model is trained to recover missing words in the input) worked best and that the most important factor was the computational cost;
- unlabeled datasets, where we showed that training on in-domain data can be beneficial but that pre-training on smaller datasets can lead to detrimental overfitting;
- training strategies, where we found that multitask learning could be close to competitive with a pre-train-then-fine-tune approach but requires carefully choosing how often the model is trained on each task;
- and scale, where we compare scaling up the model size, the training time, and the number of ensembled models to determine how to make the best use of fixed compute power.
Insights + Scale = State-of-the-Art
To explore the current limits of transfer learning for NLP, we ran a final set of experiments where we combined all of the best methods from our systematic study and scaled up our approach with Google Cloud TPU accelerators. Our largest model had 11 billion parameters and achieved state-of-the-art on the GLUE, SuperGLUE, SQuAD, and CNN/Daily Mail benchmarks. One particularly exciting result was that we achieved a near-human score on the SuperGLUE natural language understanding benchmark, which was specifically designed to be difficult for machine learning models but easy for humans.
Extensions
T5 is flexible enough to be easily modified for application to many tasks beyond those considered in our paper, often with great success. Below, we apply T5 to two novel tasks: closed-book question answering and fill-in-the-blank text generation with variable-sized blanks.
Closed-Book Question Answering
One way to use the text-to-text framework is on reading comprehension problems, where the model is fed some context along with a question and is trained to find the question's answer from the context. For example, one might feed the model the text from the Wikipedia article about Hurricane Connie along with the question "On what date did Hurricane Connie occur?" The model would then be trained to find the date "August 3rd, 1955" in the article. In fact, we achieved state-of-the-art results on the Stanford Question Answering Dataset (SQuAD) with this approach.
In our Colab demo and follow-up paper, we trained T5 to answer trivia questions in a more difficult "closed-book" setting, without access to any external knowledge. In other words, in order to answer a question T5 can only use knowledge stored in its parameters that it picked up during unsupervised pre-training. This can be considered a constrained form of open-domain question answering.
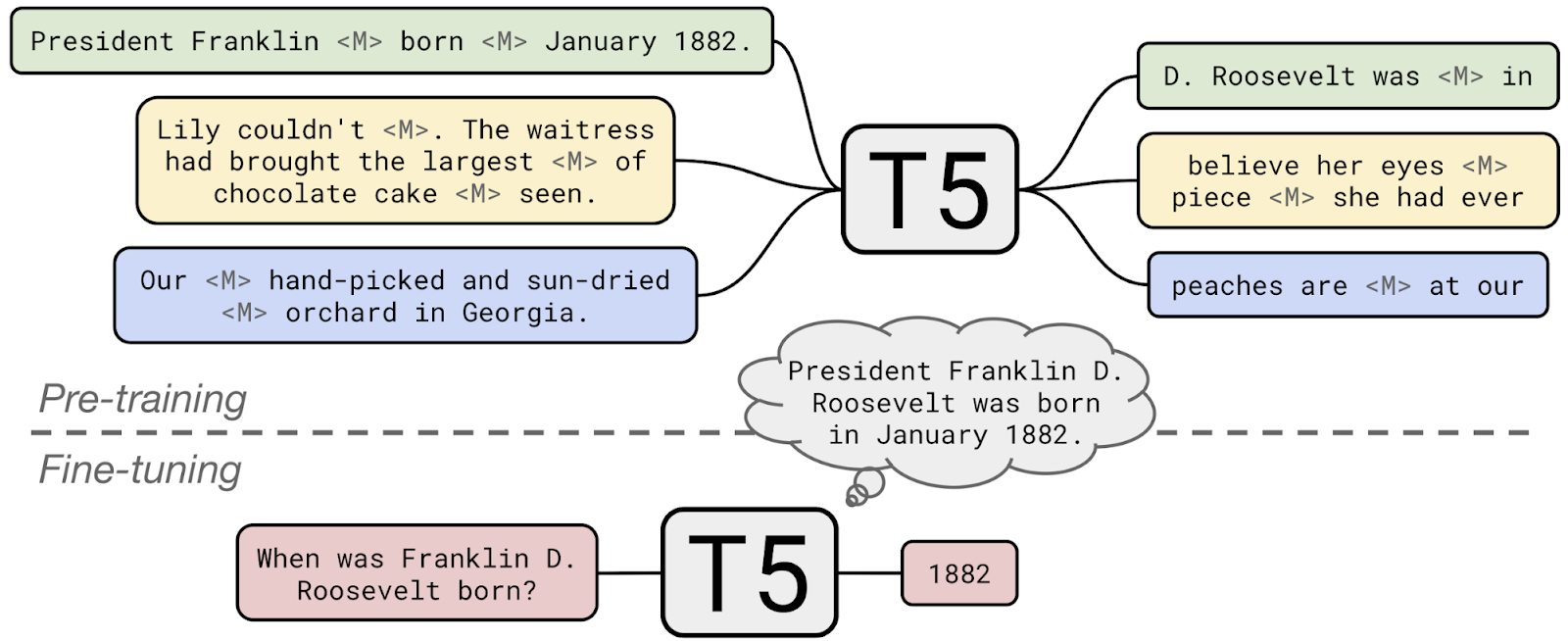 |
| During pre-training, T5 learns to fill in dropped-out spans of text (denoted by <M>) from documents in C4. To apply T5 to closed-book question answer, we fine-tuned it to answer questions without inputting any additional information or context. This forces T5 to answer questions based on “knowledge” that it internalized during pre-training. |
T5 is surprisingly good at this task. The full 11-billion parameter model produces the exact text of the answer 50.1%, 37.4%, and 34.5% of the time on TriviaQA, WebQuestions, and Natural Questions, respectively. To put these results in perspective, the T5 team went head-to-head with the model in a pub trivia challenge and lost! Try it yourself by clicking the animation below.

Fill-in-the-Blank Text Generation
Large language models like GPT-2 excel at generating very realistic looking-text since they are trained to predict what words come next after an input prompt. This has led to numerous creative applications like Talk To Transformer and the text-based game AI Dungeon. The pre-training objective used by T5 aligns more closely with a fill-in-the-blank task where the model predicts missing words within a corrupted piece of text. This objective is a generalization of the continuation task, since the “blanks” can appear at the end of the text as well.
To make use of this objective, we created a new downstream task called sized fill-in-the-blank, where the model is asked to replace a blank with a specified number of words. For example, if we give the model the input “I like to eat peanut butter and _4_ sandwiches,” we would train it to fill in the blank with approximately 4 words.
We fine-tuned T5 on this task using C4 and found the resulting outputs to be quite realistic. It’s especially fun to see how the model adjusts its predictions based on the requested size for the missing text. For example, with the input, “I love peanut butter and _N_ sandwiches,” the outputs looked like:
- I love peanut butter and jelly sandwiches.
- I love peanut butter and jelly on my sandwiches.
- I love peanut butter and jelly, which is what makes good sandwiches.
- I love peanut butter and jelly, Yum! You can’t beat peanut butter and jelly sandwiches.
- I love peanut butter and bread. Thanks!! This looks delicious. I love all types of peanut butter, but especially peanut butter/jam sandwiches.
- I love peanut butter and banana sandwiches and the Peanut Butter Chocolate Chip Cookie Bites are now very easy to prepare. The best part is that the PB&J Cookie Bites are the perfect size for kid lunch boxes and everyone will enjoy them. Kids love these sandwiches.
- I love peanut butter and jelly! It's like an incredible childhood love now that I'm in my 30s. I'm obsessed with peanut butter and jelly sandwiches. I have made this recipe many times with great success. I'm guessing you could probably find that it's from a 1950s cookbook. I haven't seen it listed in a current one but it is in a 1930 version (they seem to have retired it). Hope you enjoy it ;) I hope you'll post what you do with your sandwiches.
- I love peanut butter and banana sandwiches. Peanut butter and bananas were the original sandwich spread (also known as PB&J or Peanut Butter and Jelly), so they are probably my favorite. When I was a kid, I knew what peanut butter and bananas tasted like, but I didn't really think of them as one flavor. I did recognize PB & J's as just a sandwich spread, and not really two separate flavours. When I was in graduate school researching food allergies and intolerances, PB&B is one of the main themes that came up. PB&B was and still is the favorite sandwich spread on my school cafeteria tray, and it's still on my personal board in the kitchen. I've seen PB&B on more than one occasion over the years. I can always find one of the other types of peanut butter spread at the school cafeteria and I find it's the perfect spread for PB&B. You have several options for making your own peanut butter (I love this recipe from Cookie and Kate) or buying it at stores like Trader Joes, Publix, and Safeway. The flavor of PB&B varies, but I've found that white chocolate is my favorite to use. This simple sandwich is perfect for lunch or an afternoon snack. When you're on the go, you can use a store bought product, but it just wouldn't taste as good. These peanut butter n' banana sandwich spreads (as well as other peanut butter spreads) are great for on the go eating, but they can also be refrigerated for a few hours and then served at your next party. Preheat oven to 350 degrees. Using a kitchen timer, or using a microwave, heat butter in a saucepan and melt over low heat. Add vanilla extract and milk and heat until nearly boiling. Add peanut butter, bananas, sugar, salt, and pepper, mixing well to combine all ingredients. Spread peanut butter mixture on both sides of your bread. Top with banana slices and a slice of cheese. Toast the bread until both sides are golden brown. Remove from toast and sprinkle a little more sugar and peanut butter on the top. Enjoy while the bread is warm. Store in an airtight container up to one day. Assemble peanut butter and banana sandwich spread by spreading the peanut butter mixture on each slice of bread. Add a banana slice on top and then a PB & J sandwich. Enjoy while the bread is still warm. P.S. You might also like these peanut butter and jelly sandwiches.
Conclusion
We are excited to see how people use our findings, code, and pre-trained models to help jump-start their projects. Check out the Colab Notebook to get started, and share how you use it with us on Twitter!
Acknowledgements
This work has been a collaborative effort involving Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu, Karishma Malkan, Noah Fiedel, and Monica Dinculescu.
Other posts of interest
-

April 23, 2024
Safely repairing broken builds with ML- Machine Intelligence ·
- Software Systems & Engineering
-

April 12, 2024
Contrastive neural audio separation- Machine Intelligence ·
- Sound & Accoustics
-

April 11, 2024
Patchscopes: A unifying framework for inspecting hidden representations of language models- Machine Intelligence ·
- Natural Language Processing ·
- Responsible AI