A Scalable Approach to Reducing Gender Bias in Google Translate
April 22, 2020
Posted by Melvin Johnson, Senior Software Engineer, Google Research
Machine learning (ML) models for language translation can be skewed by societal biases reflected in their training data. One such example, gender bias, often becomes more apparent when translating between a gender-specific language and one that is less-so. For instance, Google Translate historically translated the Turkish equivalent of “He/she is a doctor” into the masculine form, and the Turkish equivalent of “He/she is a nurse” into the feminine form.
In line with Google’s AI Principles, which emphasizes the importance to avoid creating or reinforcing unfair biases, in December 2018 we announced gender-specific translations. This feature in Google Translate provides options for both feminine and masculine translations when translating queries that are gender-neutral in the source language. For this work, we developed a three-step approach, which involved detecting gender-neutral queries, generating gender-specific translations and checking for accuracy. We used this approach to enable gender-specific translations for phrases and sentences in Turkish-to-English and have now expanded this approach for English-to-Spanish translations, the most popular language-pair in Google Translate.
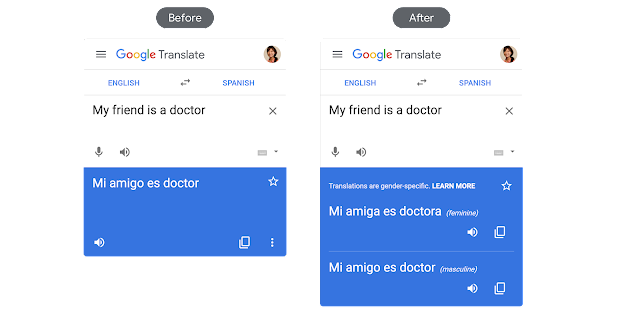
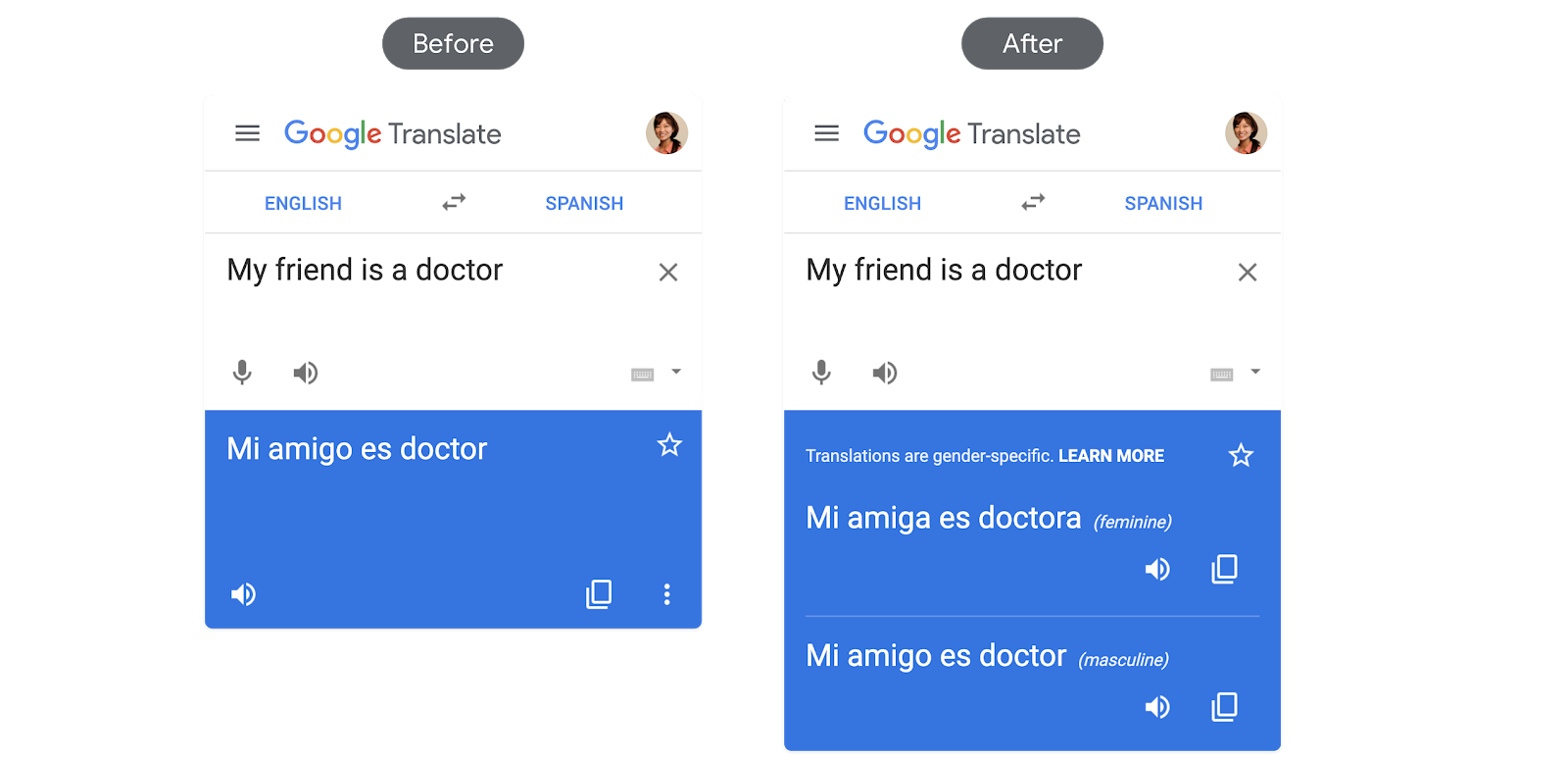 |
| Left: Early example of the translation of a gender neutral English phrase to a gender-specific Spanish counterpart. In this case, only a biased example is given. Right: The new Translate provides both a feminine and a masculine translation option. |
But as this approach was applied to more languages, it became apparent that there were issues in scaling. Specifically, generating masculine and feminine translations independently using a neural machine translation (NMT) system resulted in low recall, failing to show gender-specific translations for up to 40% of eligible queries, because the two translations often weren’t exactly equivalent, except for gender-related phenomena. Additionally, building a classifier to detect gender-neutrality for each source language was data intensive.
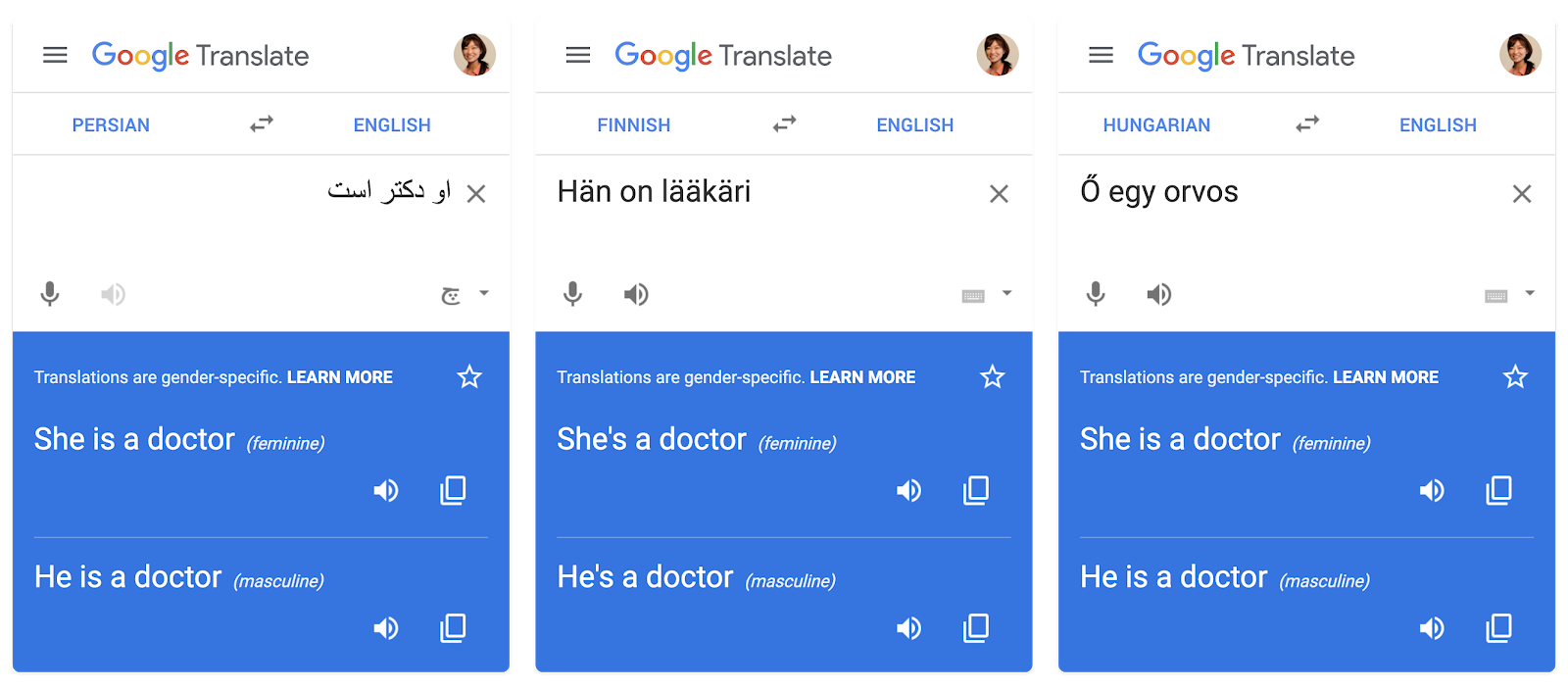
Today, along with the release of the new English-to-Spanish gender-specific translations, we announce an improved approach that uses a dramatically different paradigm to address gender bias by rewriting or post-editing the initial translation. This approach is more scalable, especially when translating from gender-neutral languages to English, since it does not require a gender-neutrality detector. Using this approach we have expanded gender-specific translations to include Finnish, Hungarian, and Persian-to-English. We have also replaced the previous Turkish-to-English system using the new rewriting-based method.
Rewriting-Based Gender-Specific Translation
The first step in the rewriting-based method is to generate the initial translation. The translation is then reviewed to identify instances where a gender-neutral source phrase yielded a gender-specific translation. If that is the case, we apply a sentence-level rewriter to generate an alternative gendered translation. Finally, both the initial and the rewritten translations are reviewed to ensure that the only difference is the gender.
 |
| Top: The original approach. Bottom: The new rewriting-based approach. |
Rewriter
Building a rewriter involved generating millions of training examples composed of pairs of phrases, each of which included both masculine and feminine translations. Because such data was not readily available, we generated a new dataset for this purpose. Starting with a large monolingual dataset, we programmatically generated candidate rewrites by swapping gendered pronouns from masculine to feminine, or vice versa. Since there can be multiple valid candidates, depending on the context — for example the feminine pronoun “her” can map to either “him” or “his” and the masculine pronoun “his” can map to “her” or “hers” — a mechanism was needed for choosing the correct one. To resolve this tie, one can either use a syntactic parser or a language model. Because a syntactic parsing model would require training with labeled datasets in each language, it is less scalable than a language model, which can learn in an unsupervised fashion. So, we select the best candidate using an in-house language model trained on millions of English sentences.
 |
| This table demonstrates the data generation process. We start with the input, generate candidates and finally break the tie using a language model. |
The above data generation process results in training data that goes from a masculine input to a feminine output and vice versa. We merge data from both these directions and train a one-layer transformer-based sequence-to-sequence model on it. We introduce punctuation and casing variants in the training data to increase the model robustness. Our final model can reliably produce the requested masculine or feminine rewrites 99% of the time.
Evaluation
We also devised a new method of evaluation, named bias reduction, which measures the relative reduction of bias between the new translation system and the existing system. Here “bias” is defined as making a gender choice in the translation that is unspecified in the source. For example, if the current system is biased 90% of the time and the new system is biased 45% of the time, this results in a 50% relative bias reduction. Using this metric, the new approach results in a bias reduction of ≥90% for translations from Hungarian, Finnish and Persian-to-English. The bias reduction of the existing Turkish-to-English system improved from 60% to 95% with the new approach. Our system triggers gender-specific translations with an average precision of 97% (i.e., when we decide to show gender-specific translations we’re right 97% of the time).
We’ve made significant progress since our initial launch by increasing the quality of gender-specific translations and also expanding it to 4 more language-pairs. We are committed to further addressing gender bias in Google Translate and plan to extend this work to document-level translation, as well.
Acknowledgements
This effort has been successful thanks to the hard work of many people, including, but not limited to the following (in alphabetical order of last name): Anja Austermann, Jennifer Choi, Hossein Emami, Rick Genter, Megan Hancock, Mikio Hirabayashi, Macduff Hughes, Tolga Kayadelen, Mira Keskinen, Michelle Linch, Klaus Macherey, Gergely Morvay, Tetsuji Nakagawa, Thom Nelson, Mengmeng Niu, Jennimaria Palomaki, Alex Rudnick, Apu Shah, Jason Smith, Romina Stella, Vilmos Urban, Colin Young, Angie Whitnah, Pendar Yousefi, Tao Yu
Other posts of interest
-

April 19, 2024
Improving Gboard language models via private federated analytics- Algorithms & Theory ·
- Distributed Systems & Parallel Computing ·
- Product ·
- Security, Privacy and Abuse Prevention
-

April 11, 2024
Patchscopes: A unifying framework for inspecting hidden representations of language models- Machine Intelligence ·
- Natural Language Processing ·
- Responsible AI
-

April 10, 2024
SOAR: New algorithms for even faster vector search with ScaNN- Algorithms & Theory ·
- Conferences & Events ·
- Data Mining & Modeling