Evaluating Natural Language Generation with BLEURT
May 26, 2020
Posted by Thibault Sellam, Software Engineer and Ankur P. Parikh, Research Scientist, Google Research
In the last few years, research in natural language generation (NLG) has made tremendous progress, with models now able to translate text, summarize articles, engage in conversation, and comment on pictures with unprecedented accuracy, using approaches with increasingly high levels of sophistication. Currently, there are two methods to evaluate these NLG systems: human evaluation and automatic metrics. With human evaluation, one runs a large-scale quality survey for each new version of a model using human annotators, but that approach can be prohibitively labor intensive. In contrast, one can use popular automatic metrics (e.g., BLEU), but these are oftentimes unreliable substitutes for human interpretation and judgement. The rapid progress of NLG and the drawbacks of existing evaluation methods calls for the development of novel ways to assess the quality and success of NLG systems.
In “BLEURT: Learning Robust Metrics for Text Generation” (presented during ACL 2020), we introduce a novel automatic metric that delivers ratings that are robust and reach an unprecedented level of quality, much closer to human annotation. BLEURT (Bilingual Evaluation Understudy with Representations from Transformers) builds upon recent advances in transfer learning to capture widespread linguistic phenomena, such as paraphrasing. The metric is available on Github.
Evaluating NLG Systems
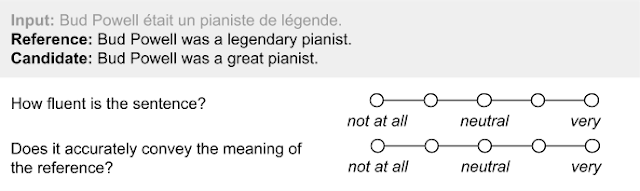
In human evaluation, a piece of generated text is presented to annotators, who are tasked with assessing its quality with respect to its fluency and meaning. The text is typically shown side-by-side with a reference, authored by a human or mined from the Web.
 |
| An example questionnaire used for human evaluation in machine translation. |
In contrast, the idea behind automatic metrics is to provide a cheap, low-latency proxy for human-quality measurements. Automatic metrics often take two sentences as input, a candidate and a reference, and they return a score that indicates to what extent the former resembles the latter, typically using lexical overlap. A popular metric is BLEU, which counts the sequences of words in the candidate that also appear in the reference (the BLEU score is very similar to precision).
The advantages and weaknesses of automatic metrics are the opposite of those that come with human evaluation. Automatic metrics are convenient — they can be computed in real-time throughout the training process (e.g., for plotting with Tensorboard). However, they are often inaccurate due to their focus on surface-level similarities and they fail to capture the diversity of human language. Frequently, there are many perfectly valid sentences that can convey the same meaning. Overlap-based metrics that rely exclusively on lexical matches unfairly reward those that resemble the reference in their surface form, even if they do not accurately capture meaning, and penalize other paraphrases.
 |
| BLEU scores for three candidate sentences. Candidate 2 is semantically close to the reference, and yet its score is lower than Candidate 3. |
Introducing BLEURT
BLEURT is a novel, machine learning-based automatic metric that can capture non-trivial semantic similarities between sentences. It is trained on a public collection of ratings (the WMT Metrics Shared Task dataset) as well as additional ratings provided by the user.
 |
| Three candidate sentences rated by BLEURT. BLEURT captures that candidate 2 is similar to the reference, even though it contains more non-reference words than candidate 3. |
To address this problem, we employ transfer learning. First, we use the contextual word representations of BERT, a state-of-the-art unsupervised representation learning method for language understanding that has already been successfully incorporated into NLG metrics (e.g., YiSi or BERTscore).
Second, we introduce a novel pre-training scheme to increase BLEURT's robustness. Our experiments reveal that training a regression model directly over publicly available human ratings is a brittle approach, since we cannot control in what domain and across what time span the metric will be used. The accuracy is likely to drop in the presence of domain drift, i.e., when the text used comes from a different domain than the training sentence pairs. It may also drop when there is a quality drift, when the ratings to be predicted are higher than those used during training — a feature which would normally be good news because it indicates that ML research is making progress.
The success of BLEURT relies on “warming-up” the model using millions of synthetic sentence pairs before fine-tuning on human ratings. We generated training data by applying random perturbations to sentences from Wikipedia. Instead of collecting human ratings, we use a collection of metrics and models from the literature (including BLEU), which allows the number of training examples to be scaled up at very low cost.
 |
| BLEURT's data generation process combines random perturbations and scoring with pre-existing metrics and models. |
We pre-train BLEURT twice, first with a language modelling objective (as explained in the original BERT paper), then with a collection of NLG evaluation objectives. We then fine-tune the model on the WMT Metrics dataset, on a set of ratings provided by the user, or a combination of both.The following figure illustrates BLEURT's training procedure end-to-end.

Results
We benchmark BLEURT against competing approaches and show that it offers superior performance, correlating well with human ratings on the WMT Metrics Shared Task (machine translation) and the WebNLG Challenge (data-to-text). For example, BLEURT is ~48% more accurate than BLEU on the WMT Metrics Shared Task of 2019. We also demonstrate that pre-training helps BLEURT cope with quality drift.
 |
| Correlation between different metrics and human ratings on the WMT'19 Metrics Shared Task. |
As NLG models have gotten better over time, evaluation metrics have become an important bottleneck for the research in this field. There are good reasons why overlap-based metrics are so popular: they are simple, consistent, and they do not require any training data. In the use cases where multiple reference sentences are available for each candidate, they can be very accurate. While they play a critical part in our infrastructure, they are also very conservative, and only give an incomplete picture of NLG systems' performance. Our view is that ML engineers should enrich their evaluation toolkits with more flexible, semantic-level metrics.
BLEURT is our attempt to capture NLG quality beyond surface overlap. Thanks to BERT's representations and a novel pre-training scheme, our metric yields SOTA performance on two academic benchmarks, and we are currently investigating how it can improve Google products. Future research includes investigating multilinguality and multimodality.
Acknowledgements
This project was co-advised by Dipanjan Das. We thank Slav Petrov, Eunsol Choi, Nicholas FitzGerald, Jacob Devlin, Madhavan Kidambi, Ming-Wei Chang, and all the members of the Google Research Language team.
Other posts of interest
-

April 11, 2024
Patchscopes: A unifying framework for inspecting hidden representations of language models- Machine Intelligence ·
- Natural Language Processing ·
- Responsible AI
-

April 10, 2024
SOAR: New algorithms for even faster vector search with ScaNN- Algorithms & Theory ·
- Conferences & Events ·
- Data Mining & Modeling
-
March 14, 2024
Cappy: Outperforming and boosting large multi-task language models with a small scorer- Machine Intelligence ·
- Machine Perception ·
- Natural Language Processing