Visual language maps for robot navigation
March 23, 2023
Posted by Oier Mees, PhD Student, University of Freiburg, and Andy Zeng, Research Scientist, Robotics at Google

People are excellent navigators of the physical world, due in part to their remarkable ability to build cognitive maps that form the basis of spatial memory — from localizing landmarks at varying ontological levels (like a book on a shelf in the living room) to determining whether a layout permits navigation from point A to point B. Building robots that are proficient at navigation requires an interconnected understanding of (a) vision and natural language (to associate landmarks or follow instructions), and (b) spatial reasoning (to connect a map representing an environment to the true spatial distribution of objects). While there have been many recent advances in training joint visual-language models on Internet-scale data, figuring out how to best connect them to a spatial representation of the physical world that can be used by robots remains an open research question.
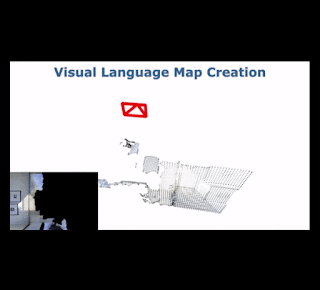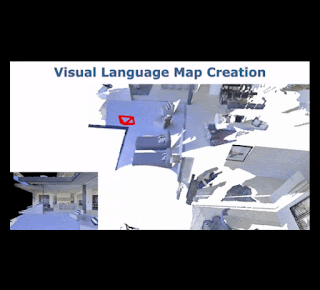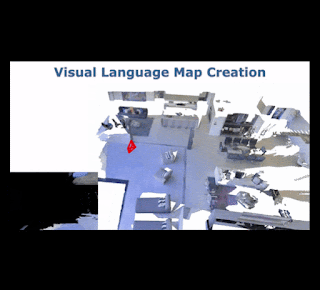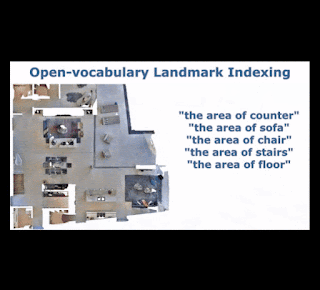
To explore this, we collaborated with researchers at the University of Freiburg and Nuremberg to develop Visual Language Maps (VLMaps), a map representation that directly fuses pre-trained visual-language embeddings into a 3D reconstruction of the environment. VLMaps, which is set to appear at ICRA 2023, is a simple approach that allows robots to (1) index visual landmarks in the map using natural language descriptions, (2) employ Code as Policies to navigate to spatial goals, such as "go in between the sofa and TV" or "move three meters to the right of the chair", and (3) generate open-vocabulary obstacle maps — allowing multiple robots with different morphologies (mobile manipulators vs. drones, for example) to use the same VLMap for path planning. VLMaps can be used out-of-the-box without additional labeled data or model fine-tuning, and outperforms other zero-shot methods by over 17% on challenging object-goal and spatial-goal navigation tasks in Habitat and Matterport3D. We are also releasing the code used for our experiments along with an interactive simulated robot demo.
| VLMaps can be built by fusing pre-trained visual-language embeddings into a 3D reconstruction of the environment. At runtime, a robot can query the VLMap to locate visual landmarks given natural language descriptions, or to build open-vocabulary obstacle maps for path planning. |
Classic 3D maps with a modern multimodal twist
VLMaps combines the geometric structure of classic 3D reconstructions with the expression of modern visual-language models pre-trained on Internet-scale data. As the robot moves around, VLMaps uses a pre-trained visual-language model to compute dense per-pixel embeddings from posed RGB camera views, and integrates them into a large map-sized 3D tensor aligned with an existing 3D reconstruction of the physical world. This representation allows the system to localize landmarks given their natural language descriptions (such as "a book on a shelf in the living room") by comparing their text embeddings to all locations in the tensor and finding the closest match. Querying these target locations can be used directly as goal coordinates for language-conditioned navigation, as primitive API function calls for Code as Policies to process spatial goals (e.g., code-writing models interpret "in between" as arithmetic between two locations), or to sequence multiple navigation goals for long-horizon instructions.
# move first to the left side of the counter, then move between the sink and the oven, then move back and forth to the sofa and the table twice.
robot.move_to_left('counter')
robot.move_in_between('sink', 'oven')
pos1 = robot.get_pos('sofa')
pos2 = robot.get_pos('table')
for i in range(2):
robot.move_to(pos1)
robot.move_to(pos2)
# move 2 meters north of the laptop, then move 3 meters rightward.
robot.move_north('laptop')
robot.face('laptop')
robot.turn(180)
robot.move_forward(2)
robot.turn(90)
robot.move_forward(3)
| VLMaps can be used to return the map coordinates of landmarks given natural language descriptions, which can be wrapped as a primitive API function call for Code as Policies to sequence multiple goals long-horizon navigation instructions. |
Results
We evaluate VLMaps on challenging zero-shot object-goal and spatial-goal navigation tasks in Habitat and Matterport3D, without additional training or fine-tuning. The robot is asked to navigate to four subgoals sequentially specified in natural language. We observe that VLMaps significantly outperforms strong baselines (including CoW and LM-Nav) by up to 17% due to its improved visuo-lingual grounding.
| Tasks | Number of subgoals in a row | Independent subgoals |
||||||||
| 1 |
2 |
3 |
4 |
|||||||
| LM-Nav | 26 | 4 | 1 | 1 | 26 | |||||
| CoW | 42 | 15 | 7 | 3 | 36 | |||||
| CLIP MAP | 33 | 8 | 2 | 0 | 30 | |||||
| VLMaps (ours) | 59 | 34 | 22 | 15 | 59 | |||||
| GT Map | 91 | 78 | 71 | 67 | 85 | |||||
| The VLMaps-approach performs favorably over alternative open-vocabulary baselines on multi-object navigation (success rate [%]) and specifically excels on longer-horizon tasks with multiple sub-goals. |
A key advantage of VLMaps is its ability to understand spatial goals, such as "go in between the sofa and TV" or "move three meters to the right of the chair”. Experiments for long-horizon spatial-goal navigation show an improvement by up to 29%. To gain more insights into the regions in the map that are activated for different language queries, we visualize the heatmaps for the object type “chair”.
 |
| The improved vision and language grounding capabilities of VLMaps, which contains significantly fewer false positives than competing approaches, enable it to navigate zero-shot to landmarks using language descriptions. |
Open-vocabulary obstacle maps
A single VLMap of the same environment can also be used to build open-vocabulary obstacle maps for path planning. This is done by taking the union of binary-thresholded detection maps over a list of landmark categories that the robot can or cannot traverse (such as "tables", "chairs", "walls", etc.). This is useful since robots with different morphologies may move around in the same environment differently. For example, "tables" are obstacles for a large mobile robot, but may be traversable for a drone. We observe that using VLMaps to create multiple robot-specific obstacle maps improves navigation efficiency by up to 4% (measured in terms of task success rates weighted by path length) over using a single shared obstacle map for each robot. See the paper for more details.
 |
| Experiments with a mobile robot (LoCoBot) and drone in AI2THOR simulated environments. Left: Top-down view of an environment. Middle columns: Agents’ observations during navigation. Right: Obstacle maps generated for different embodiments with corresponding navigation paths. |
Conclusion
VLMaps takes an initial step towards grounding pre-trained visual-language information onto spatial map representations that can be used by robots for navigation. Experiments in simulated and real environments show that VLMaps can enable language-using robots to (i) index landmarks (or spatial locations relative to them) given their natural language descriptions, and (ii) generate open-vocabulary obstacle maps for path planning. Extending VLMaps to handle more dynamic environments (e.g., with moving people) is an interesting avenue for future work.
Open-source release
We have released the code needed to reproduce our experiments and an interactive simulated robot demo on the project website, which also contains additional videos and code to benchmark agents in simulation.
Acknowledgments
We would like to thank the co-authors of this research: Chenguang Huang and Wolfram Burgard.
Other posts of interest
-

April 17, 2024
Robust speech recognition in AR through infinite virtual rooms with acoustic modeling- Human-Computer Interaction and Visualization ·
- Machine Perception ·
- Speech Processing
-

April 11, 2024
Patchscopes: A unifying framework for inspecting hidden representations of language models- Machine Intelligence ·
- Natural Language Processing ·
- Responsible AI
-
March 18, 2024
MELON: Reconstructing 3D objects from images with unknown poses- Machine Intelligence ·
- Machine Perception