
Large Scale Image Annotation: Learning to Rank with Joint Word-Image Embeddings
March 10, 2011
Posted by Jason Weston and Samy Bengio, Research Team
In our paper, we introduce a generic framework to find a joint representation of images and their labels, which can then be used for various tasks, including image ranking and image annotation.
We focus on the task of automatic assignment of annotations (text labels) to images given only the pixel representation of the image (i.e., with no known metadata). This is achieved by a learning algorithm, that is, where the computer learns to predict annotations for new images given annotated training images. Such training datasets are becoming larger and larger, with tens of millions of images and tens of thousands of possible annotations. In this paper, we propose a strongly performing method that scales to such datasets by simultaneously learning to optimize precision at the top of the ranked list of annotations for a given image and learning a low-dimensional joint embedding vector space for both images and annotations. Our system learns an interpretable model, where annotations with alternate wordings ("president obama" or "barack"), different languages ("tour eiffel" or "eiffel tower"), or similar concepts (such as "toad" or "frog") are close in the embedding space. Hence, even when our model does not predict the exact annotation given by a human labeler, it often predicts similar annotations.
Our system is trained on ~10 million images with ~100,000 possible annotation types and it annotates a single new image in ~0.17 seconds (not including feature processing) and consumes only 82MB of memory. Our method both outperforms all the methods we tested against and in comparison to them is faster and consumes less memory, making it possible to house such a system on a laptop or mobile device.
-
Labels:
- Machine Perception
Other posts of interest
-

April 17, 2024
Robust speech recognition in AR through infinite virtual rooms with acoustic modeling- Human-Computer Interaction and Visualization ·
- Machine Perception ·
- Speech Processing
-
March 18, 2024
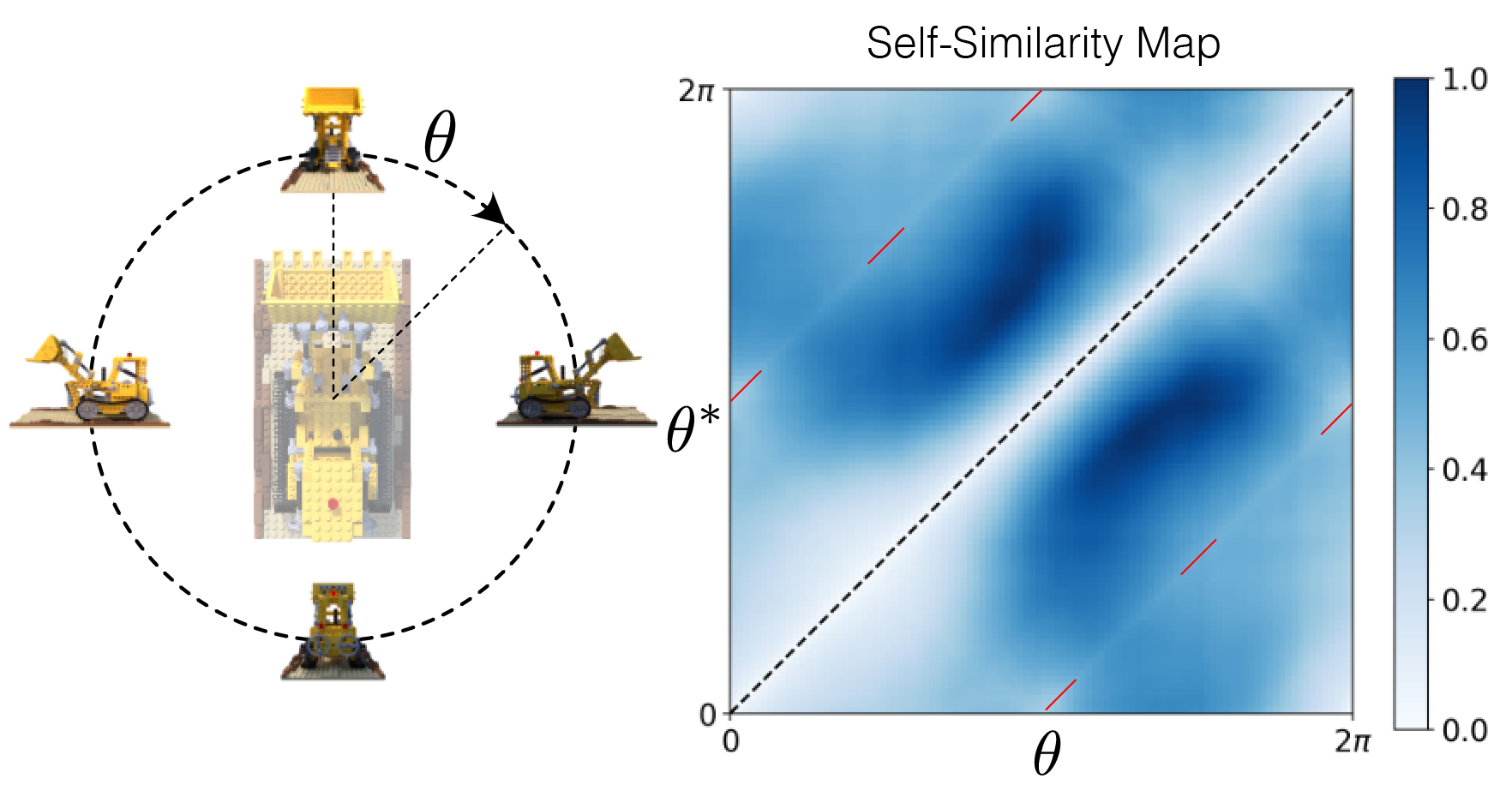
MELON: Reconstructing 3D objects from images with unknown poses- Machine Intelligence ·
- Machine Perception
-
March 14, 2024
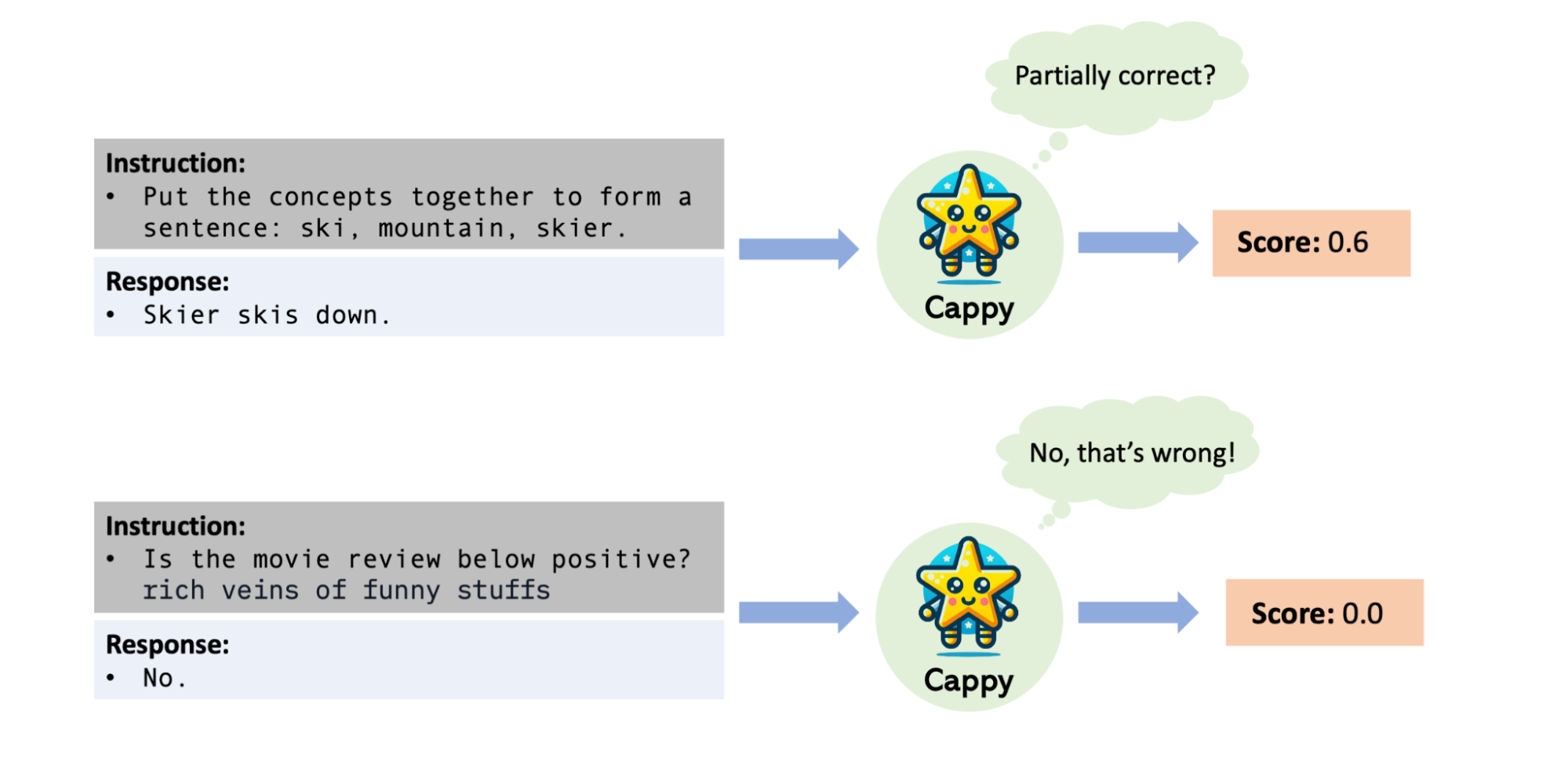
Cappy: Outperforming and boosting large multi-task language models with a small scorer- Machine Intelligence ·
- Machine Perception ·
- Natural Language Processing