Advancing Research on Video Understanding with the YouTube-BoundingBoxes Dataset
February 6, 2017
One of the most challenging research areas in machine learning today is enabling computers to understand what a scene is about. For example, while humans know that a ball that disappears behind a wall only to reappear a moment later is very likely the same object, this is not at all obvious to an algorithm. Understanding this requires not only a global picture of what objects are contained in each frame of a video, but also where those objects are located within the frame and their locations over time. Just last year we published YouTube-8M, a dataset consisting of automatically labelled YouTube videos. And while this helps further progress in the field, it is only one piece to the puzzle.
Today, in order to facilitate progress in video understanding research, we are introducing YouTube-BoundingBoxes, a dataset consisting of 5 million bounding boxes spanning 23 object categories, densely labeling segments from 210,000 YouTube videos. To date, this is the largest manually annotated video dataset containing bounding boxes, which track objects in temporally contiguous frames. The dataset is designed to be large enough to train large-scale models, and be representative of videos captured in natural settings. Importantly, the human-labelled annotations contain objects as they appear in the real world with partial occlusions, motion blur and natural lighting.
 |
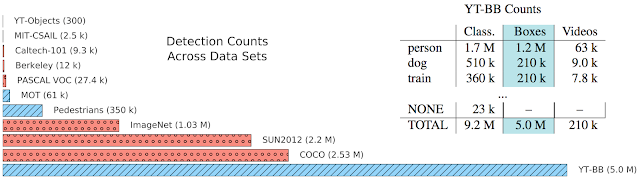
| Summary of dataset statistics. Bar Chart: Relative number of detections in existing image (red) and video (blue) data sets. The YouTube BoundingBoxes dataset (YT-BB) is at the bottom, is at the bottom. Table: The three columns are counts for: classification annotations, bounding boxes, and unique videos with bounding boxes. Full details on the dataset can be found in the preprint. |
 |
| Three video segments, sampled at 1 frame per second. The final frame of each example shows how it is visually challenging to recognize the bounded object, due to blur or occlusion (train example, blue arrow). However, temporally-related frames, where the object has been more clearly identified, can allow object classes to be inferred. Note how only visible parts are included in the box: the orange arrow in the bear example (middle row) points to the hidden head. The dog example illustrates tight bounding boxes that track the tail (orange arrows) and foot (blue arrows). The airplane example illustrates how partial objects are annotated (first frame) tracked across changes in perspective, occlusions and camera cuts. |
Acknowledgements
This work was greatly helped along by Xin Pan, Thomas Silva, Mir Shabber Ali Khan, Ashwin Kakarla and many others, as well as support and advice from Manfred Georg, Sami Abu-El-Haija, Susanna Ricco and George Toderici.