
Announcing AVA: A Finely Labeled Video Dataset for Human Action Understanding
October 19, 2017
Posted by Chunhui Gu & David Ross, Software Engineers
Teaching machines to understand human actions in videos is a fundamental research problem in Computer Vision, essential to applications such as personal video search and discovery, sports analysis, and gesture interfaces. Despite exciting breakthroughs made over the past years in classifying and finding objects in images, recognizing human actions still remains a big challenge. This is due to the fact that actions are, by nature, less well-defined than objects in videos, making it difficult to construct a finely labeled action video dataset. And while many benchmarking datasets, e.g., UCF101, ActivityNet and DeepMind’s Kinetics, adopt the labeling scheme of image classification and assign one label to each video or video clip in the dataset, no dataset exists for complex scenes containing multiple people who could be performing different actions.
In order to facilitate further research into human action recognition, we have released AVA, coined from “atomic visual actions”, a new dataset that provides multiple action labels for each person in extended video sequences. AVA consists of URLs for publicly available videos from YouTube, annotated with a set of 80 atomic actions (e.g. “walk”, “kick (an object)”, “shake hands”) that are spatial-temporally localized, resulting in 57.6k video segments, 96k labeled humans performing actions, and a total of 210k action labels. You can browse the website to explore the dataset and download annotations, and read our arXiv paper that describes the design and development of the dataset.
Compared with other action datasets, AVA possesses the following key characteristics:
- Person-centric annotation. Each action label is associated with a person rather than a video or clip. Hence, we are able to assign different labels to multiple people performing different actions in the same scene, which is quite common.
- Atomic visual actions. We limit our action labels to fine temporal scales (3 seconds), where actions are physical in nature and have clear visual signatures.
- Realistic video material. We use movies as the source of AVA, drawing from a variety of genres and countries of origin. As a result, a wide range of human behaviors appear in the data.
 |
| Examples of 3-second video segments (from Video Source) with their bounding box annotations in the middle frame of each segment. (For clarity, only one bounding box is shown for each example.) |
To create AVA, we first collected a diverse set of long form content from YouTube, focusing on the “film” and “television” categories, featuring professional actors of many different nationalities. We analyzed a 15 minute clip from each video, and uniformly partitioned it into 300 non-overlapping 3-second segments. The sampling strategy preserved sequences of actions in a coherent temporal context.
Next, we manually labeled all bounding boxes of persons in the middle frame of each 3-second segment. For each person in the bounding box, annotators selected a variable number of labels from a pre-defined atomic action vocabulary (with 80 classes) that describe the person’s actions within the segment. These actions were divided into three groups: pose/movement actions, person-object interactions, and person-person interactions. Because we exhaustively labeled all people performing all actions, the frequencies of AVA’s labels followed a long-tail distribution, as summarized below.
 |
| Distribution of AVA’s atomic action labels. Labels displayed in the x-axis are only a partial set of our vocabulary. |
The unique design of AVA allows us to derive some interesting statistics that are not available in other existing datasets. For example, given the large number of persons with at least two labels, we can measure the co-occurrence patterns of action labels. The figure below shows the top co-occurring action pairs in AVA with their co-occurrence scores. We confirm expected patterns such as people frequently play instruments while singing, lift a person while playing with kids, and hug while kissing.
 |
| Top co-occurring action pairs in AVA. |
To evaluate the effectiveness of human action recognition systems on the AVA dataset, we implemented an existing baseline deep learning model that obtains highly competitive performance on the much smaller JHMDB dataset. Due to challenging variations in zoom, background clutter, cinematography, and appearance variation, this model achieves a relatively modest performance when correctly identifying actions on AVA (18.4% mAP). This suggests that AVA will be a useful testbed for developing and evaluating new action recognition architectures and algorithms for years to come.
We hope that the release of AVA will help improve the development of human action recognition systems, and provide opportunities to model complex activities based on labels with fine spatio-temporal granularity at the level of individual person’s actions. We will continue to expand and improve AVA, and are eager to hear feedback from the community to help us guide future directions. Please join the AVA users mailing list to receive dataset updates as well as to send us emails for feedback.
Acknowledgements
The core team behind AVA includes Chunhui Gu, Chen Sun, David Ross, Caroline Pantofaru, Yeqing Li, Sudheendra Vijayanarasimhan, George Toderici, Susanna Ricco, Rahul Sukthankar, Cordelia Schmid, and Jitendra Malik. We thank many Google colleagues and annotators for their dedicated support on this project.
Other posts of interest
-

April 17, 2024
Robust speech recognition in AR through infinite virtual rooms with acoustic modeling- Human-Computer Interaction and Visualization ·
- Machine Perception ·
- Speech Processing
-
March 28, 2024
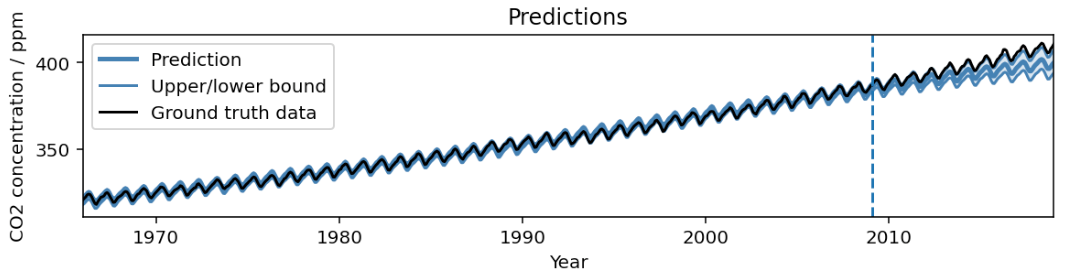
AutoBNN: Probabilistic time series forecasting with compositional bayesian neural networks- Algorithms & Theory ·
- Machine Intelligence ·
- Open Source Models & Datasets
-
March 19, 2024
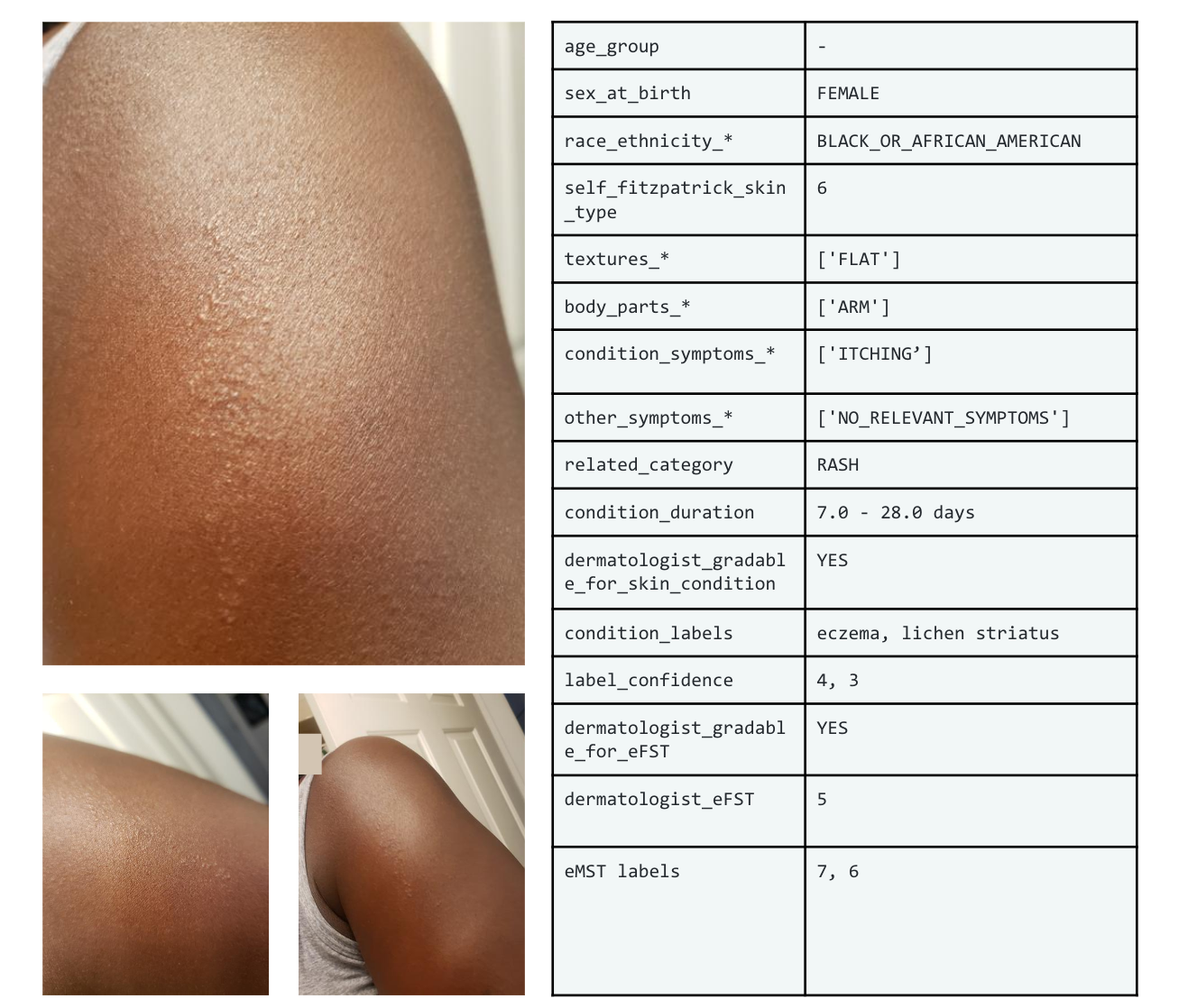
SCIN: A new resource for representative dermatology images- Education Innovation ·
- Health & Bioscience ·
- Open Source Models & Datasets