
Introducing the Kaggle “Quick, Draw!” Doodle Recognition Challenge
September 28, 2018
Posted by Thomas Deselaers, Senior Staff Software Engineer and Jake Walker, Product Manager, Machine Perception
Online handwriting recognition consists of recognizing structured patterns in freeform handwritten input. While Google products like Translate, Keep and Handwriting Input use this technology to recognize handwritten text, it works for any predefined pattern for which enough training data is available. The same technology that lets you digitize handwritten text can also be used to improve your drawing abilities and build virtual worlds, and represents an exciting research direction that explores the potential of handwriting as a human-computer interaction modality. For example the “Quick, Draw!” game generated a dataset of 50M drawings (out of more than 1B that were drawn) which itself inspired many different new projects.
In order to encourage further research in this exciting field, we have launched the Kaggle "Quick, Draw!" Doodle Recognition Challenge, which tasks participants to build a better machine learning classifier for the existing “Quick, Draw!” dataset. Importantly, since the training data comes from the game itself (where drawings can be incomplete or may not match the label), this challenge requires the development of a classifier that can effectively learn from noisy data and perform well on a manually-labeled test set from a different distribution.
The Dataset
In the original “Quick, Draw!” game, the player is prompted to draw an image of a certain category (dog, cow, car, etc). The player then has 20 seconds to complete the drawing - if the computer recognizes the drawing correctly within that time, the player earns a point. Each game consists of 6 randomly chosen categories.
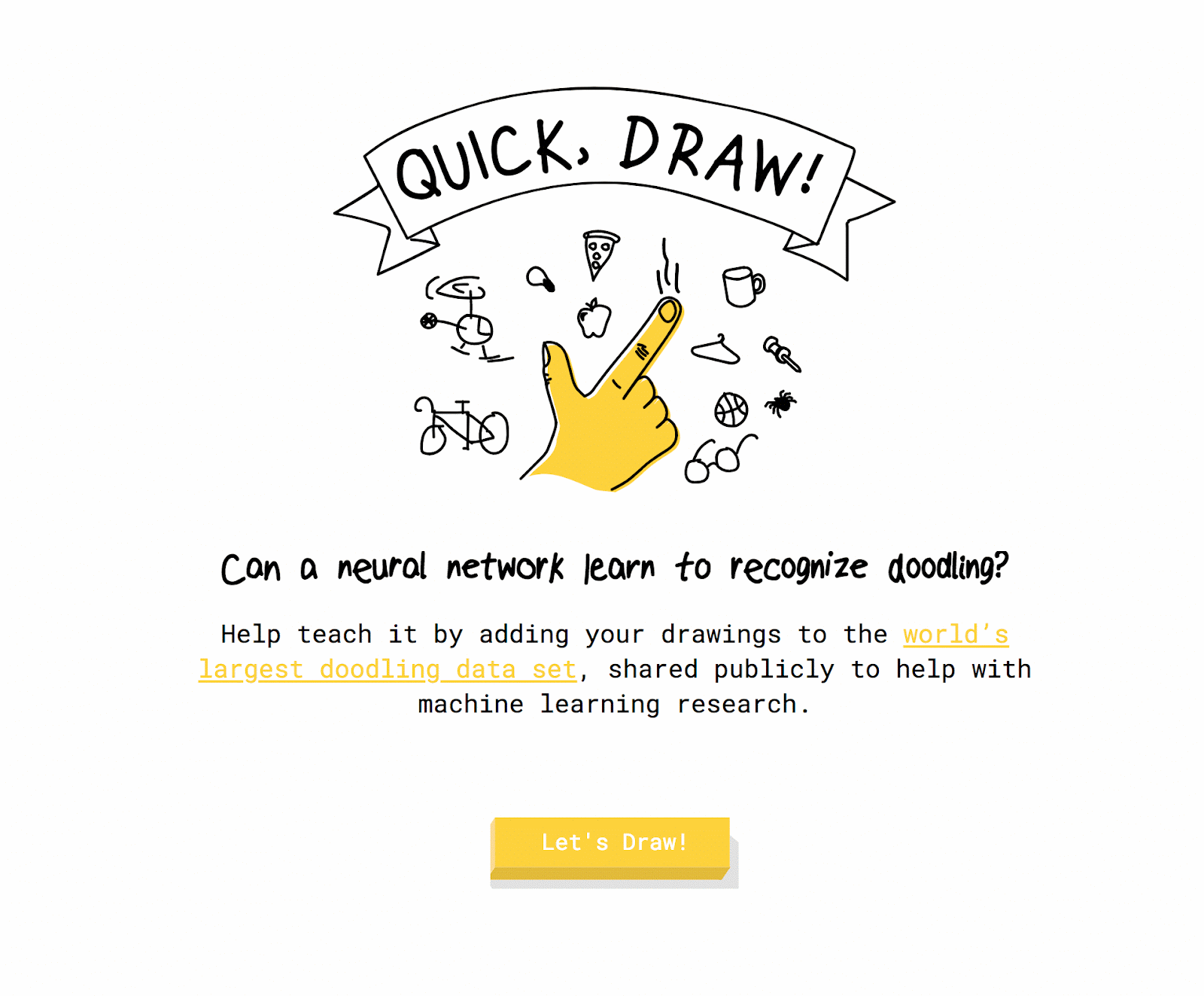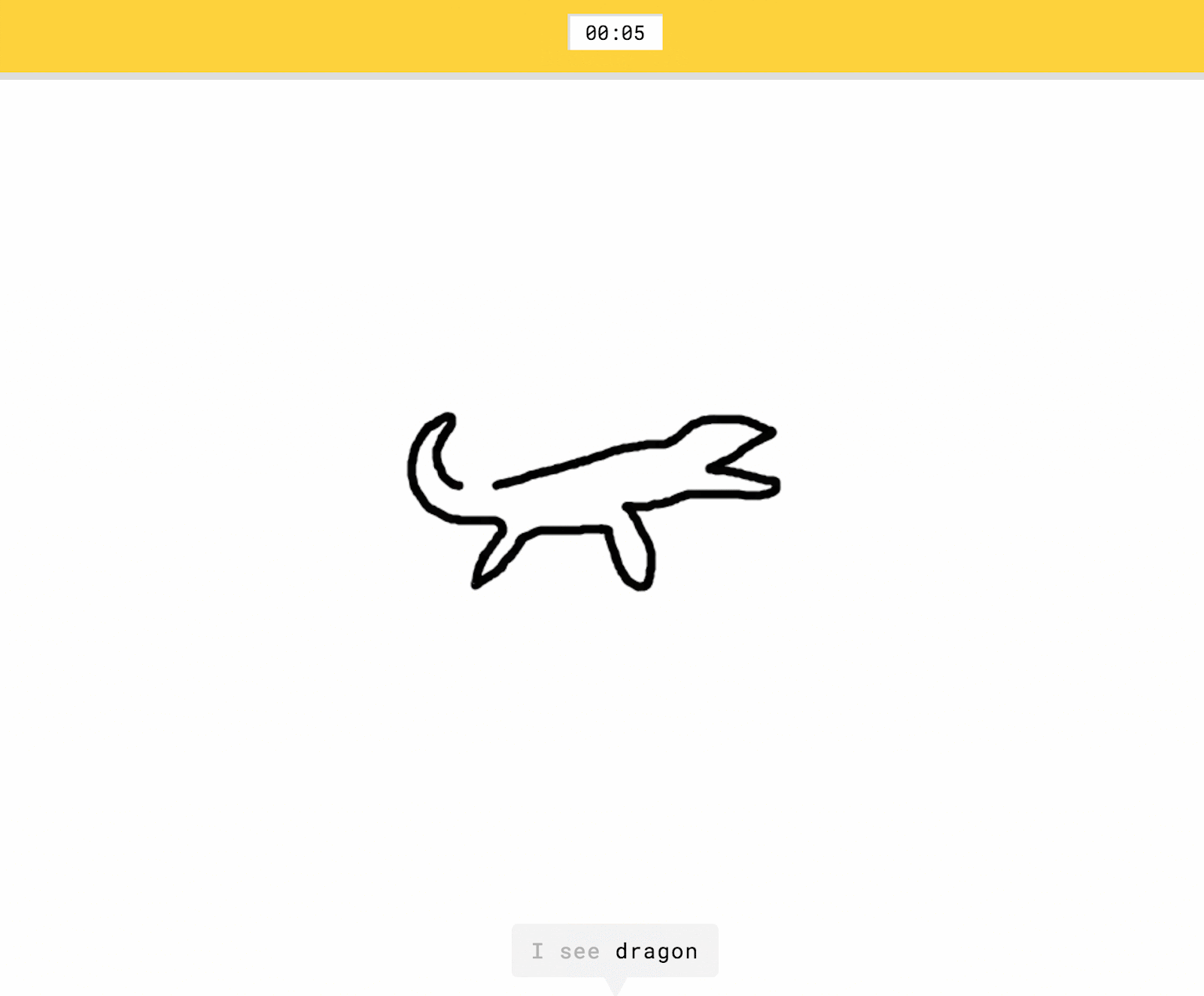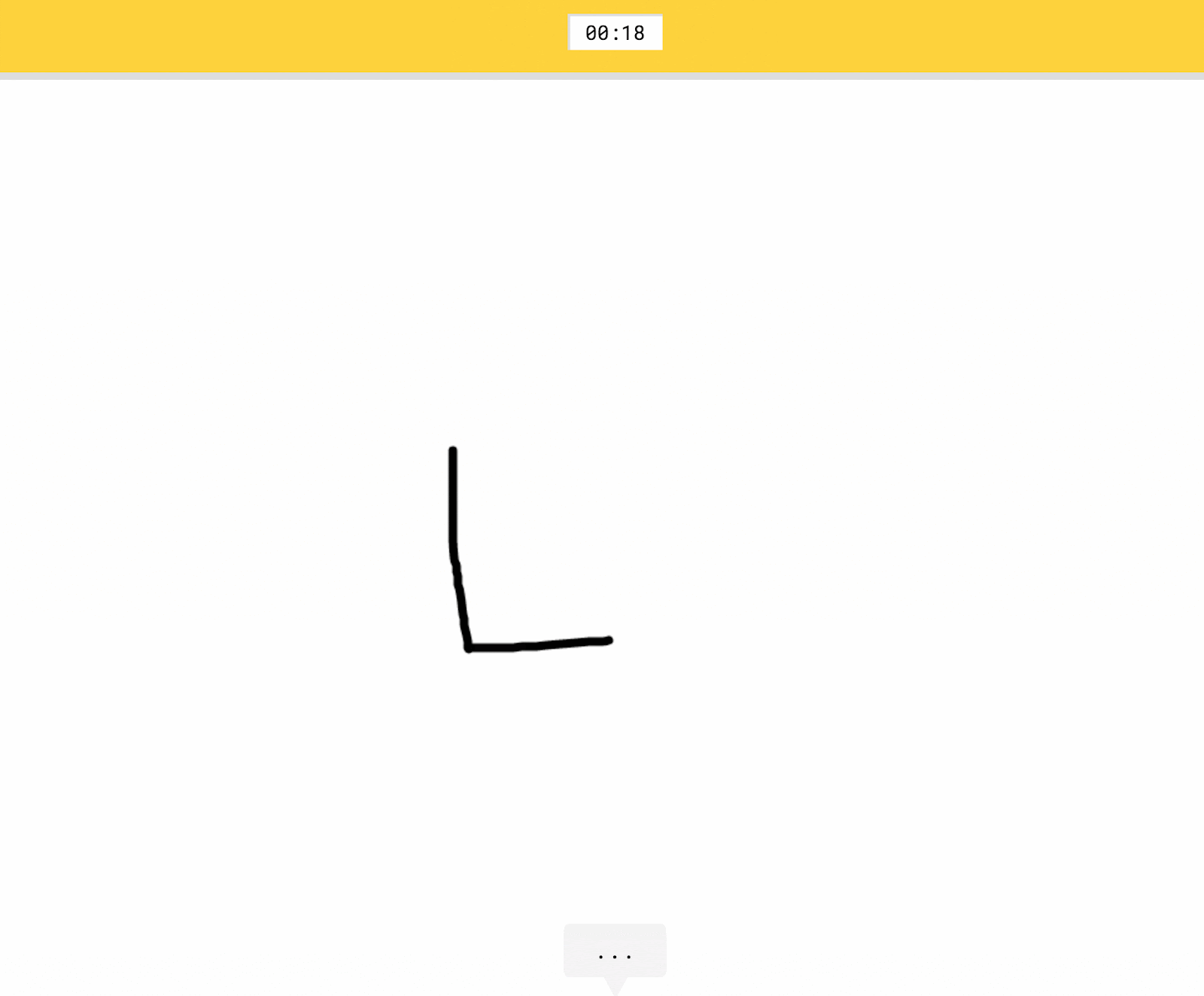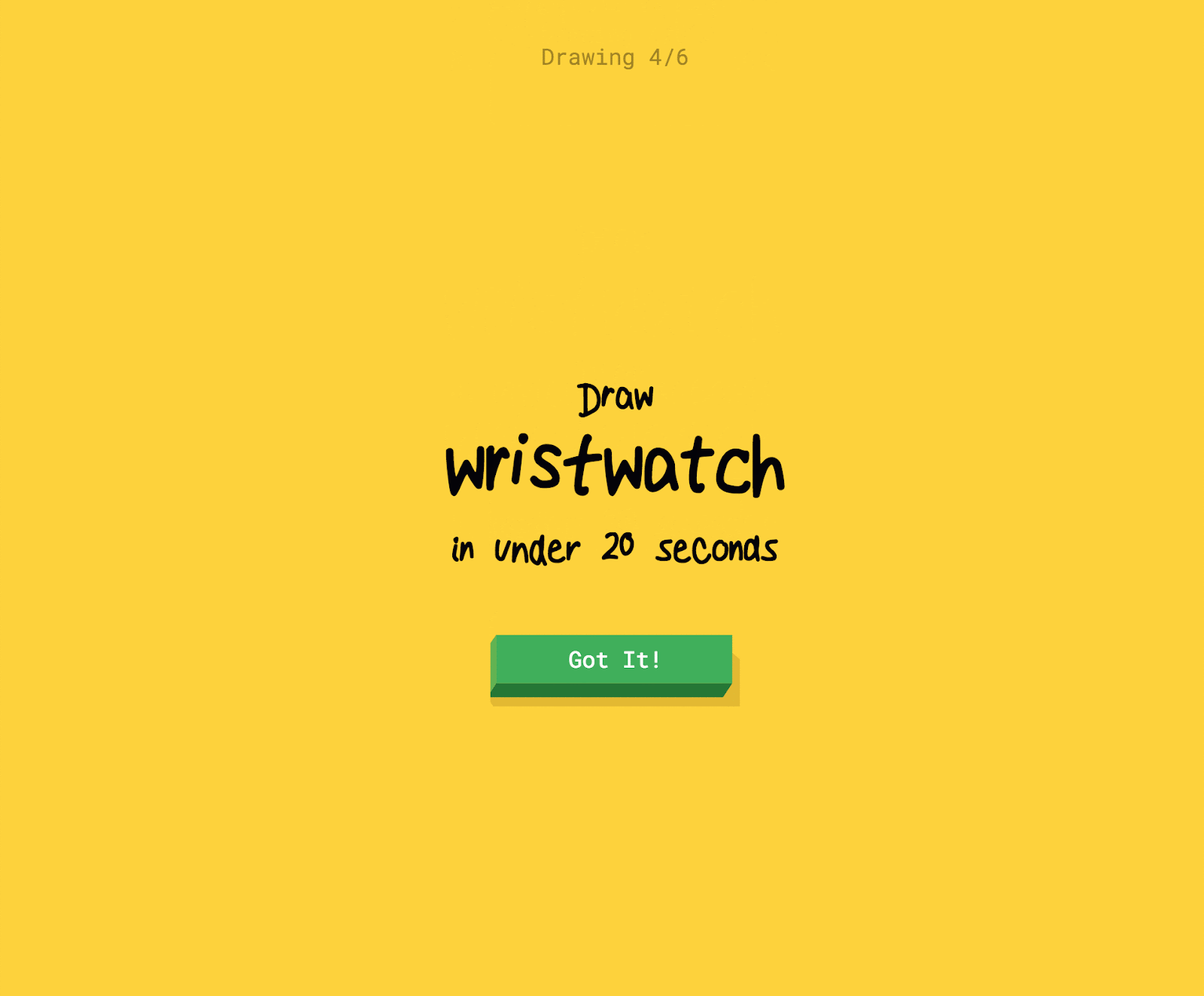
- Correct: the user drew the prompted category and the computer only recognized it correctly after the user was done drawing.
- Correct, but incomplete: the user drew the prompted category and the computer recognized it correctly before the user had finished. Incompleteness can vary from nearly ready to only a fraction of the category drawn. This is probably fairly common in images that are marked as recognized correctly.
- Correct, but not recognized correctly: The player drew the correct category but the AI never recognized it. Some players react to this by adding more details. Others scribble out and try again.
- Incorrect: some players have different concepts in mind when they see a word - e.g. in the category seesaw, we have observed a number of saw drawings.
Get Started
We’ve previously published a tutorial that uses this dataset, and now we're inviting the community to build on this or other approaches to achieve even higher accuracy. You can get started by visiting the challenge website and going through the existing kernels which allow you to analyze the data and visualize it. We’re looking forward to learning about the approaches that the community comes up with for the competition and how much you can improve on our original production model.
Acknowledgements
We'd like to thank everyone who worked with us on this, particularly Jonas Jongejan and Brenda Fogg from the Creative Lab team, Julia Elliott and Walter Reade from the Kaggle team, and the handwriting recognition team.
Other posts of interest
-

April 23, 2024
Safely repairing broken builds with ML- Machine Intelligence ·
- Software Systems & Engineering
-

April 17, 2024
Robust speech recognition in AR through infinite virtual rooms with acoustic modeling- Human-Computer Interaction and Visualization ·
- Machine Perception ·
- Speech Processing
-

April 12, 2024
Contrastive neural audio separation- Machine Intelligence ·
- Sound & Accoustics