
Toward Human-Centered Design for ML Frameworks
March 3, 2020
Posted by Carrie J. Cai, Senior Research Scientist, Google Research and Philip J. Guo, Assistant Professor, UC San Diego
Quick links
As machine learning (ML) increasingly impacts diverse stakeholders and social groups, it has become necessary for a broader range of developers — even those without formal ML training — to be able to adapt and apply ML to their own problems. In recent years, there have been many efforts to lower the barrier to machine learning, by abstracting complex model behavior into higher-level APIs. For instance, Google has been developing TensorFlow.js, an open-source framework that lets developers write ML code in JavaScript to run directly in web browsers. Despite the abundance of engineering work towards improving APIs, little is known about what non-ML software developers actually need to successfully adopt ML into their daily work practices. Specifically, what do they struggle with when trying modern ML frameworks, and what do they want these frameworks to provide?
In “Software Developers Learning Machine Learning: Motivations, Hurdles, and Desires,” which received a Best Paper Award at the IEEE conference on Visual Languages and Human-Centric Computing (VL/HCC), we share our research on these questions and report the results from a large-scale survey of 645 people who used TensorFlow.js. The vast majority of respondents were software or web developers, who were fairly new to machine learning and usually did not use ML as part of their primary job. We examined the hurdles experienced by developers when using ML frameworks and explored the features and tools that they felt would best assist in their adoption of these frameworks into their programming workflows.
What Do Developers Struggle With Most When Using ML Frameworks?
Interestingly, by far the most common challenge reported by developers was not the lack of a clear API, but rather their own lack of conceptual understanding of ML, which hindered their ability to successfully use ML frameworks. These hurdles ranged from the initial stages of picking a good problem to which they could apply TensorFlow.js (e.g., survey respondents reported not knowing “what to apply ML to, where ML succeeds, where it sucks”), to creating the architecture of a neural net (e.g., “how many units [do] I have to put in when adding layers to the model?”) and knowing how to set and tune parameters during model training (e.g., “deciding what optimizers, loss functions to use”). Without a conceptual understanding of how different parameters affect outcomes, developers often felt overwhelmed by the seemingly infinite space of parameters to tune when debugging ML models.
Without sufficient conceptual support, developers also found it hard to transfer lessons learned from “hello world” API tutorials to their own real-world problems. While API tutorials provide syntax for implementing specific models (e.g., classifying MNIST digits), they typically don't provide the underlying conceptual scaffolding necessary to generalize beyond that specific problem.
Developers often attributed these challenges to their own lack of experience in advanced mathematics. Ironically, despite the abundance of non-experts tinkering with ML frameworks nowadays, many felt that ML frameworks were intended for specialists with advanced training in linear algebra and calculus, and thus not meant for general software developers or product managers. This semblance of imposter syndrome may be fueled by the prevalence of esoteric mathematical terminology in API documentation, which may unintentionally give the impression that an advanced math degree is necessary for even practical integration of ML into software projects. Though math training is indeed beneficial, the ability to grasp and apply practical concepts (e.g., a model’s learning rate) to real-world problems does not require an advanced math degree.
What Do Developers Want From ML Frameworks?
Developers who responded to our survey wanted ML frameworks to teach them not only how to use the API, but also the unspoken idioms that would help them to effectively apply the framework to their own problems.
Pre-made Models with Explicit Support for Modification
A common desire was to have access to libraries of canonical ML models, so that they could modify an existing template rather than creating new ones from scratch. Currently, pre-trained models are being made more widely available in many ML platforms, including TensorFlow.js. However, in their current form, these models do not provide explicit support for novice consumption. For example, in our survey, developers reported substantial hurdles transferring and modifying existing model examples to their own use cases. Thus, the provision of pre-made ML models should also be coupled with explicit support for modification.
Synthesize ML Best Practices into Just-in-Time Hints
Developers also wished frameworks could provide ML best practices, i.e., practical tips and tricks that they could use when designing or debugging models. While ML experts may acquire heuristics and go-to strategies through years of dedicated trial and error, the mere decision overhead of “which parameter should I try tuning first?” can be overwhelming for developers who aren't ML experts. To help narrow this broad space of decision possibilities, ML frameworks could embed tips on best practices directly into the programming workflow. Currently, visualizations like TensorBoard and tfjs-vis make it possible to help see what's going on inside of their models.
Coupling these with just-in-time strategic pointers, such as whether to adapt a pre-trained model or to build one from scratch, or diagnostic checks, like practical tips to “decrease learning rate” if the model is not converging, could help users acquire and make use of practical strategies. These tips could serve as an intermediate scaffolding layer that helps demystify the math theory underlying ML into developer-friendly terms.
Support for Learning-by-Doing
Finally, even though ML frameworks are not traditional learning platforms, software developers are indeed treating them as lightweight vehicles for learning-by-doing. For example, one survey respondent appreciated when conceptual support was tightly interwoven into the framework, rather than being a separate resource: “...the small code demos that you can edit and run right there. Really helps basic understanding.” Another explained that “I prefer learning by doing, so I would like to see more tutorials, examples” embedded into ML frameworks. Some found it difficult to take a formal online course, and would rather learn in bite-sized pieces through hands-on tinkering: “Due to the rest of life, I have to fit learning into small 5-15 minute blocks.”
Given these desires to learn-by-doing, ML frameworks may need to more clearly distinguish between a spectrum of resources aimed at different levels of expertise. Although many frameworks already have “hello world” tutorials, to properly set expectations these frameworks could more explicitly differentiate between API (syntax-specific) onboarding and ML (conceptual) onboarding.
Looking Forward
Ultimately, as the frontiers of ML are still evolving, providing practical, conceptual tips for software developers and creating a shared reservoir of community-curated best practices can benefit ML experts and novices alike. Hopefully, these research findings pave the way for more user-centric designs of future ML frameworks.
Acknowledgements
This work would not have been possible without Yannick Assogba, Sandeep Gupta, Lauren Hannah-Murphy, Michael Terry, Ann Yuan, Nikhil Thorat, Daniel Smilkov, Martin Wattenberg, Fernanda Viegas, and members of PAIR and TensorFlow.js.
Quick links
Other posts of interest
-
March 20, 2025
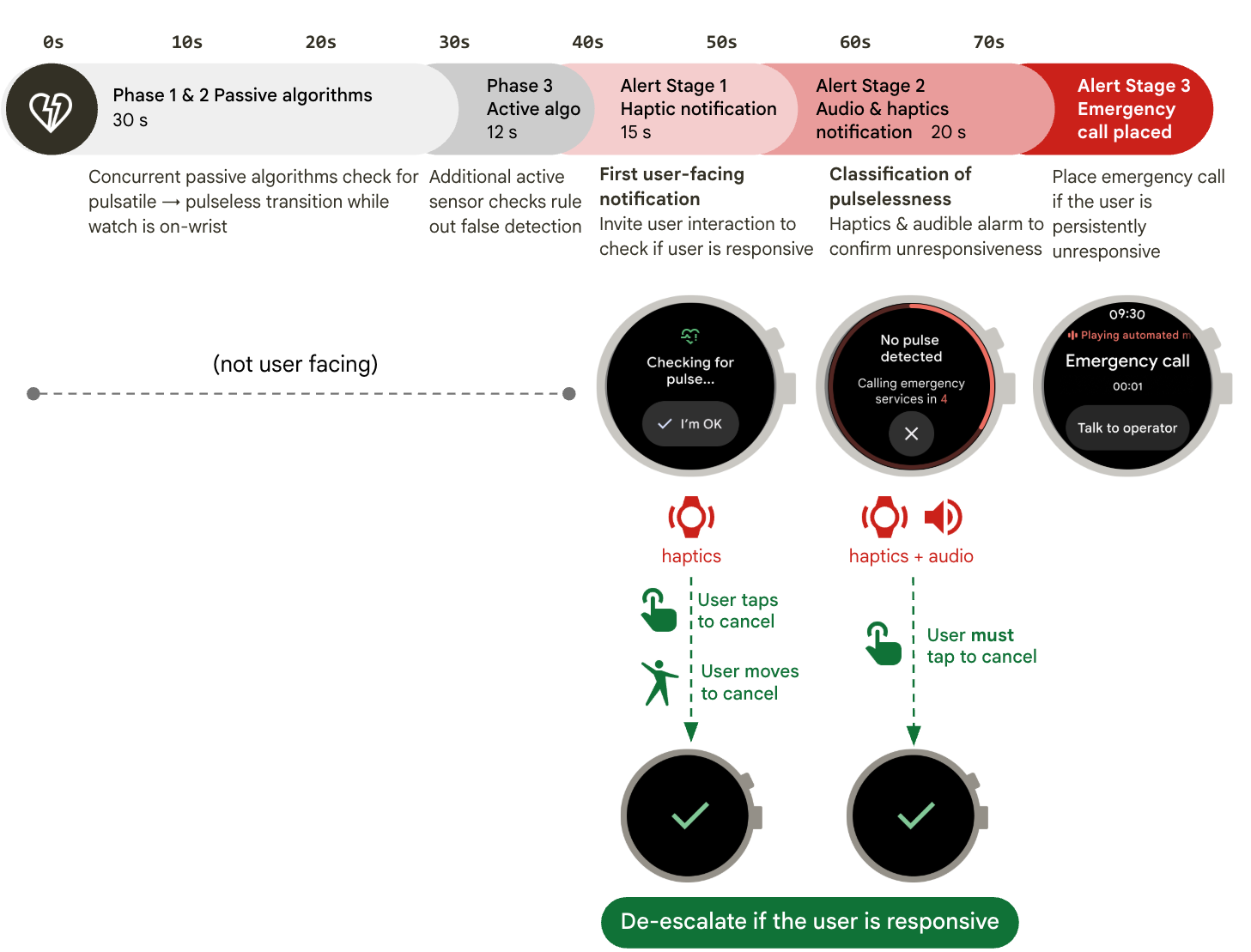
Loss of Pulse Detection on the Google Pixel Watch 3- Health & Bioscience ·
- Mobile Systems ·
- Product
-

March 18, 2025
Generating synthetic data with differentially private LLM inference- Machine Intelligence ·
- Natural Language Processing ·
- Security, Privacy and Abuse Prevention
-
February 28, 2025
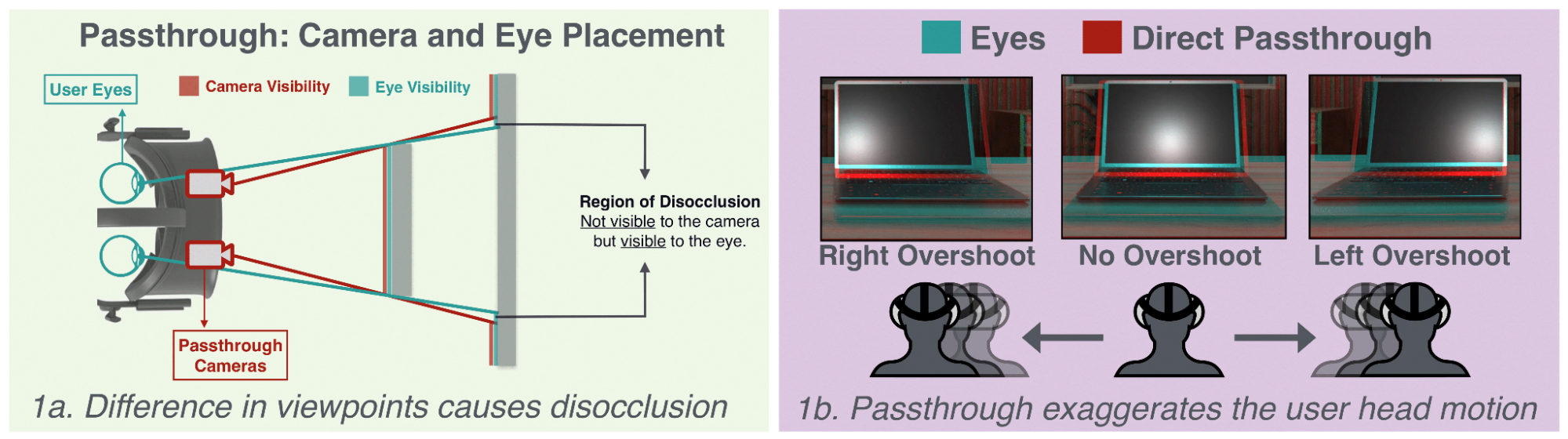
Mind the GAP: Geometry Aware Passthrough mitigates cybersickness- Human-Computer Interaction and Visualization ·
- Machine Perception