
Advancing Self-Supervised and Semi-Supervised Learning with SimCLR
April 8, 2020
Posted by Ting Chen, Research Scientist and Geoffrey Hinton, VP & Engineering Fellow, Google Research
Recently, natural language processing models, such as BERT and T5, have shown that it is possible to achieve good results with few class labels by first pretraining on a large unlabeled dataset and then fine-tuning on a smaller labeled dataset. Similarly, pretraining on large unlabeled image datasets has the potential to improve performance on computer vision tasks, as demonstrated by Exemplar-CNN, Instance Discrimination, CPC, AMDIM, CMC, MoCo and others. These methods fall under the umbrella of self-supervised learning, which is a family of techniques for converting an unsupervised learning problem into a supervised one by creating surrogate labels from the unlabeled dataset. However, current self-supervised techniques for image data are complex, requiring significant modifications to the architecture or the training procedure, and have not seen widespread adoption.
In “A Simple Framework for Contrastive Learning of Visual Representations”, we outline a method that not only simplifies but also improves previous approaches to self-supervised representation learning on images. Our proposed framework, called SimCLR, significantly advances the state of the art on self- supervised and semi-supervised learning and achieves a new record for image classification with a limited amount of class-labeled data (85.8% top-5 accuracy using 1% of labeled images on the ImageNet dataset). The simplicity of our approach means that it can be easily incorporated into existing supervised learning pipelines. In what follows, we first introduce the SimCLR framework, then discuss three things we discovered while developing SimCLR.
The SimCLR framework
SimCLR first learns generic representations of images on an unlabeled dataset, and then it can be fine-tuned with a small amount of labeled images to achieve good performance for a given classification task. The generic representations are learned by simultaneously maximizing agreement between differently transformed views of the same image and minimizing agreement between transformed views of different images, following a method called contrastive learning. Updating the parameters of a neural network using this contrastive objective causes representations of corresponding views to “attract” each other, while representations of non-corresponding views “repel” each other.
To begin, SimCLR randomly draws examples from the original dataset, transforming each example twice using a combination of simple augmentations (random cropping, random color distortion, and Gaussian blur), creating two sets of corresponding views. The rationale behind these simple transformations of individual images is (1) we want to encourage "consistent" representation of the same image under transformations, (2) since the pretraining data lacks labels, we can’t know a priori which image contains which object class, and 3) we found that these simple transformations are suffice for the neural net to learn good representations, though more sophisticated transformation policy can also be incorporated.
SimCLR then computes the image representation using a convolutional neural network variant based on the ResNet architecture. Afterwards, SimCLR computes a non-linear projection of the image representation using a fully-connected network (i.e., MLP), which amplifies the invariant features and maximizes the ability of the network to identify different transformations of the same image. We use stochastic gradient descent to update both CNN and MLP in order to minimize the loss function of the contrastive objective. After pre-training on the unlabeled images, we can either directly use the output of the CNN as the representation of an image, or we can fine-tune it with labeled images to achieve good performance for downstream tasks.
 |
| An illustration of the proposed SimCLR framework. The CNN and MLP layers are trained simultaneously to yield projections that are similar for augmented versions of the same image, while being dissimilar for different images, even if those images are of the same class of object. The trained model not only does well at identifying different transformations of the same image, but also learns representations of similar concepts (e.g., chairs vs. dogs), which later can be associated with labels through fine-tuning. |
Despite its simplicity, SimCLR greatly advances the state of the art in self-supervised and semi-supervised learning on ImageNet. A linear classifier trained on top of self-supervised representations learned by SimCLR achieves 76.5% / 93.2% top-1 / top-5 accuracy, compared to 71.5% / 90.1% from the previous best (CPC v2), matching the performance of supervised learning in a smaller model, ResNet-50, as demonstrated in the following figure.
 |
| ImageNet top-1 accuracy of linear classifiers trained on representations learned with different self-supervised methods (pretrained on ImageNet). Gray cross indicates supervised ResNet-50. |
Understanding Contrastive Learning of Representations
The improvement SimCLR provides over previous methods is not due to any single design choice, but to their combination. Several important findings are summarized below.
- Finding 1: The combinations of image transformations used to generate corresponding views are critical.
As SimCLR learns representations via maximizing agreement of different views of the same image, it is important to compose image transformations to prevent trivial forms of agreement, such as agreement of the color histograms. To understand this better, we explored different types of transformations, illustrated in the figure below.
We found that while no single transformation (that we studied) suffices to define a prediction task that yields the best representations, two transformations stand out: random cropping and random color distortion. Although neither cropping nor color distortion leads to high performance on its own, composing these two transformations leads to state-of-the-art results.
Random examples of transformations applied to the original image.
To understand why combining random cropping with random color distortion is important, consider the process of maximizing agreement between two crops of the same image. This naturally encompasses two types of prediction tasks that enable effective representation learning: (a) predicting local views (e.g., crop A in the image below) from a larger, “global” view (crop B), and (b) predicting neighboring views (e.g., between crop C and crop D).
However, different crops of the same image usually look very similar in color space. If the colors are left intact, a model can maximize agreement between crops simply by matching the color histograms. In this case, the model might focus solely on color and ignore other more generalizable features. By independently distorting the colors of each crop, these shallow clues can be removed, and the model can only achieve agreement by learning useful and generalizable representations.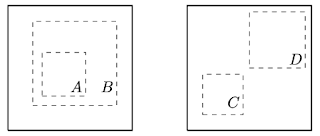
Maximizing agreement between different crops leads to two prediction tasks. Left: Global vs local views. Right: Adjacent views.
- Finding 2: The nonlinear projection is important.
In SimCLR, a MLP-based nonlinear projection is applied before the loss function for contrastive learning objective is calculated, which helps to identify the invariant features of each input image and maximize the ability of the network to identify different transformations of the same image. In our experiments, we found that using such a nonlinear projection helps improve the representation quality, improving the performance of a linear classifier trained on the SimCLR-learned representation by more than 10%.
Interestingly, comparison between the representations used as input for the MLP projection module and the output from the projection reveals that the earlier stage representations perform better when measured by a linear classifier. Since the loss function for contrastive objective is based on the output of the projection, it is somewhat surprising that the representation before the projection is better. We conjecture that our objective leads the final layer of the network to become invariant to features such as color that may be useful for downstream tasks. With the extra nonlinear projection head, the representation layer before the projection head is able to retain more useful information about the image.
- Finding 3: Scaling up significantly improves performance.
We found that (1) processing more examples in the same batch, (2) using bigger networks, and (3) training for longer all lead to significant improvements. While these may seem like somewhat obvious observations, these improvements seem larger for SimCLR than for supervised learning. For example, we observe that the performance of a supervised ResNet peaked between 90 and 300 training epochs (on ImageNet), but SimCLR can continue its improvement even after 800 epochs of training. It also seems to be the case when we increase the depth or width of the network — the gain for SimCLR continues, while it starts to saturate for supervised learning. In order to optimize the returns of scaling up our training, we made extensive use of Cloud TPU in our experiments.


To accelerate research in self-supervised and semi-supervised learning, we are excited to share the code and pretrained models of SimCLR with the larger academic community. They can be found on our GitHub repository.
Acknowledgements
This is a joint work with Simon Kornblith and Mohammad Norouzi. We would like to thank Tom Small for the visualization of the SimCLR framework. We are also grateful for general support from Google Research teams in Toronto and elsewhere.
-
Labels:
- Machine Intelligence
Other posts of interest
-

April 23, 2024
Safely repairing broken builds with ML- Machine Intelligence ·
- Software Systems & Engineering
-

April 12, 2024
Contrastive neural audio separation- Machine Intelligence ·
- Sound & Accoustics
-

April 11, 2024
Patchscopes: A unifying framework for inspecting hidden representations of language models- Machine Intelligence ·
- Natural Language Processing ·
- Responsible AI