Improving Audio Quality in Duo with WaveNetEQ
April 1, 2020
Pablo Barrera, Software Engineer, Google Research and Florian Stimberg, Research Engineer, DeepMind
Quick links
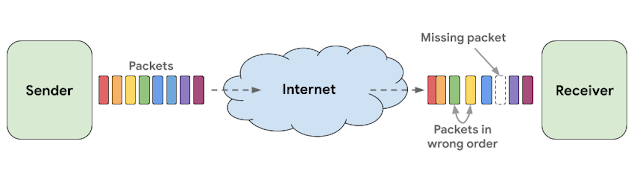
Online calls have become an everyday part of life for millions of people by helping to streamline their work and connect them to loved ones. To transmit a call across the internet, the data from calls are split into short chunks, called packets. These packets make their way over the network from the sender to the receiver where they are reassembled to make continuous streams of video and audio. However, packets often arrive at the other end in the wrong order or at the wrong time, an issue generally referred to as jitter, and sometimes individual packets can be lost entirely. Issues such as these lead to lower call quality, since the receiver has to try and fill in the gaps, and are a pervasive problem for both audio and video transmission. For example, 99% of Google Duo calls need to deal with packet losses, excessive jitter or network delays. Of those calls, 20% lose more than 3% of the total audio duration due to network issues, and 10% of calls lose more than 8%.
 |
| Simplified diagram of network problems leading to packet loss, which needs to be counteracted by the receiver to allow reliable real-time communication. |
In order to ensure reliable real-time communication, it is necessary to deal with packets that are missing when the receiver needs them. Specifically, if new audio is not provided continuously, glitches and gaps will be audible, but repeating the same audio over and over is not an ideal solution, as it produces artifacts and reduces the overall quality of the call. The process of dealing with the missing packets is called packet loss concealment (PLC). The receiver’s PLC module is responsible for creating audio (or video) to fill in the gaps created by packet losses, excessive jitter or temporary network glitches, all three of which result in an absence of data.
To address these audio issues, we present WaveNetEQ, a new PLC system now being used in Duo. WaveNetEQ is a generative model, based on DeepMind’s WaveRNN technology, that is trained using a large corpus of speech data to realistically continue short speech segments enabling it to fully synthesize the raw waveform of missing speech. Because Duo calls are end-to-end encrypted, all processing needs to be done on-device. The WaveNetEQ model is fast enough to run on a phone, while still providing state-of-the-art audio quality and more natural sounding PLC than other systems currently in use.
A New PLC System for Duo
Like many other web-based communication systems, Duo is based on the WebRTC open source project. To conceal the effects of packet loss, WebRTC’s NetEQ component uses signal processing methods, which analyze the speech and produce a smooth continuation that works very well for small losses (20ms or less), but does not sound good when the number of missing packets leads to gaps of 60ms or more. In those latter cases the speech becomes robotic and repetitive, a characteristic sound that is unfortunately familiar to many internet voice callers.
To better manage packet loss, we replace the NetEQ PLC component with a modified version of WaveRNN, a recurrent neural network model for speech synthesis consisting of two parts, an autoregressive network and a conditioning network. The autoregressive network is responsible for the continuity of the signal and provides the short-term and mid-term structure for the speech by having each generated sample depend on the network’s previous outputs. The conditioning network influences the autoregressive network to produce audio that is consistent with the more slowly-moving input features.
However, WaveRNN, like its predecessor WaveNet, was created with the text-to-speech (TTS) application in mind. As a TTS model, WaveRNN is supplied with the information of what it is supposed to say and how to say it. The conditioning network directly receives this information as input in form of the phonemes that make up the words and additional prosody features (i.e., all non-text information like intonation or pitch). In a way, the conditioning network can “see into the future” and then steer the autoregressive network towards the right waveforms to match it. In the case of a PLC system and real-time communication, this context is not provided.
For a functional PLC system, one must both extract contextual information from the current speech (i.e., the past), and generate a plausible sound to continue it. Our solution, WaveNetEQ, does both at the same time, using the autoregressive network to provide the audio continuation during a packet loss event, and the conditioning network to model long term features, like voice characteristics. The spectrogram of the past audio signal is used as input for the conditioning network, which extracts limited information about the prosody and textual content. This condensed information is fed to the autoregressive network, which combines it with the audio of the recent past to predict the next sample in the waveform domain.
This differs slightly from the procedure that was followed during training of the WaveNetEQ model, where the autoregressive network receives the actual sample present in the training data as input for the next step, rather than using the last sample it produced. This process, called teacher forcing, assures that the model learns valuable information, even at an early stage of training when its predictions are still of low quality. Once the model is fully trained and put to use in an audio or video call, teacher forcing is only used to "warm up" the model for the first sample, and after that its own output is passed back as input for the next step.
 |
| WaveNetEQ architecture. During inference, we "warm up" the autoregressive network by teacher forcing with the most recent audio. Afterwards, the model is supplied with its own output as input for the next step. A MEL spectrogram from a longer audio part is used as input for the conditioning network. |
The model is applied to the audio data in Duo's jitter buffer. Once the real audio continues after a packet loss event, we seamlessly merge the synthetic and real audio stream. In order to find the best alignment between the two signals, the model generates slightly more output than is required and then cross-fades from one to the other. This makes the transition smooth and avoids noticeable noise.
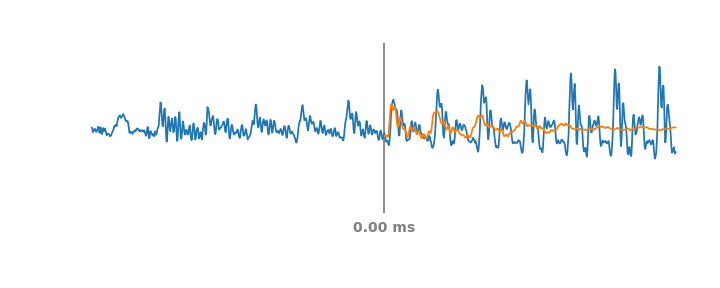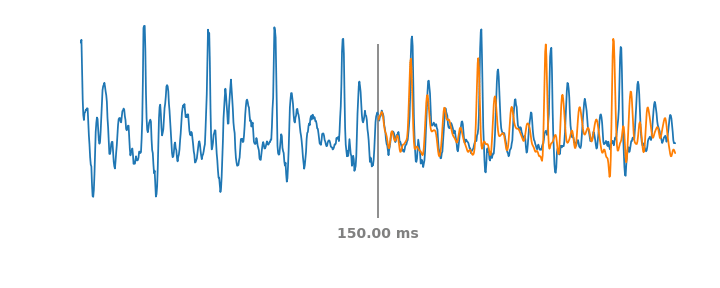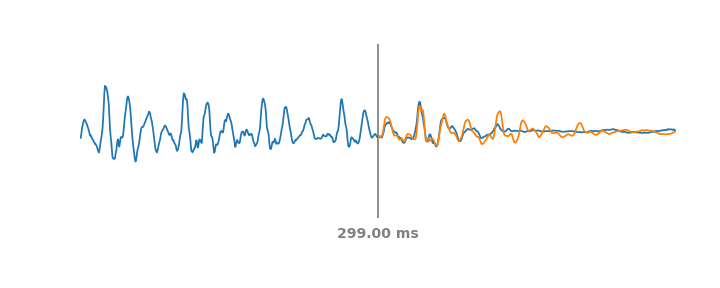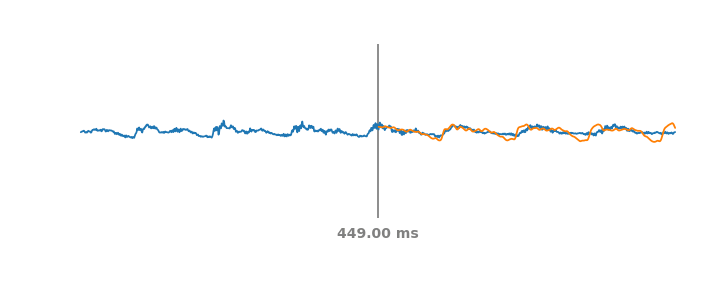 |
| Simulation of PLC events on audio over a moving span of 60 ms. The blue line represents the real audio signal, including past and future parts of the PLC event. At each timestep the orange line represents the synthetic audio WaveNetEQ would predict if the audio were to cut out at the vertical grey line. |
| 60 ms Packet Loss | |
| NetEQ | |
| WaveNetEQ | |
| NetEQ | |
| WaveNetEQ | |
| 120 ms Packet Loss | |
| NetEQ | |
| WaveNetEQ | |
| NetEQ | |
| WaveNetEQ |
| Audio clips: Comparison of WebRTC’s default PLC system, NetEQ, with our model, WaveNetEQ. Audio clips were taken from LibriTTS and 10% of the audio was dropped in 60 or 120 ms chunks and then filled in by the PLC systems. |
Ensuring Robustness
One important factor during PLC is the ability of the network to adapt to variable input signals, including different speakers or changes in background noise. In order to ensure the robustness of the model across a wide range of users, we trained WaveNetEQ on a speech dataset that contains over 100 speakers in 48 different languages, which allows the model to learn the characteristics of human speech in general, instead of the properties of a specific language. To ensure WaveNetEQ is able to deal with noisy environments, such as answering your phone in the train station or in the cafeteria, we augment the data by mixing it with a wide variety of background noises.
While our model learns how to plausibly continue speech, this is only true on a short scale — it can finish a syllable but does not predict words, per se. Instead, for longer packet losses we gradually fade out until the model only produces silence after 120 milliseconds. To further ensure that the model is not generating false syllables, we evaluated samples from WaveNetEQ and NetEQ using the Google Cloud Speech-to-Text API and found no significant difference in the word error rate, i.e., how many mistakes were made transcribing the spoken text.
We have been experimenting with WaveNetEQ in Duo, where the feature has demonstrated a positive impact on call quality and user experience. WaveNetEQ is already available in all Duo calls on Pixel 4 phones and is now being rolled out to additional models.
Acknowledgements
The core team includes Alessio Bazzica, Niklas Blum, Lennart Kolmodin, Henrik Lundin, Alex Narest, Olga Sharonova from Google and Tom Walters from DeepMind. We would also like to thank Martin Bruse (Google), Norman Casagrande, Ray Smith, Chenjie Gu and Erich Elsen (DeepMind) for their contributions.
Quick links
Other posts of interest
-
March 21, 2025
Deciphering language processing in the human brain through LLM representations- General Science ·
- Health & Bioscience ·
- Natural Language Processing ·
- Speech Processing
-
March 20, 2025
Loss of Pulse Detection on the Google Pixel Watch 3- Health & Bioscience ·
- Mobile Systems ·
- Product
-
March 4, 2025
Discovering new words with confidential federated analytics- Mobile Systems ·
- Security, Privacy and Abuse Prevention ·
- Software Systems & Engineering