Recent Advances in Google Translate
June 8, 2020
Posted by Isaac Caswell and Bowen Liang, Software Engineers, Google Research
Quick links
Advances in machine learning (ML) have driven improvements to automated translation, including the GNMT neural translation model introduced in Translate in 2016, that have enabled great improvements to the quality of translation for over 100 languages. Nevertheless, state-of-the-art systems lag significantly behind human performance in all but the most specific translation tasks. And while the research community has developed techniques that are successful for high-resource languages like Spanish and German, for which there exist copious amounts of training data, performance on low-resource languages, like Yoruba or Malayalam, still leaves much to be desired. Many techniques have demonstrated significant gains for low-resource languages in controlled research settings (e.g., the WMT Evaluation Campaign), however these results on smaller, publicly available datasets may not easily transition to large, web-crawled datasets.
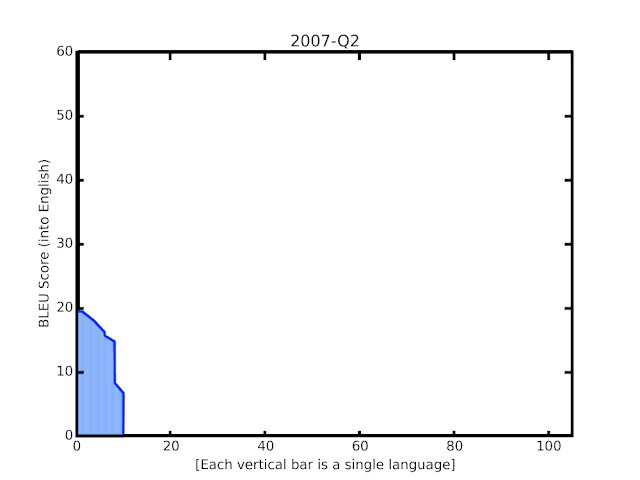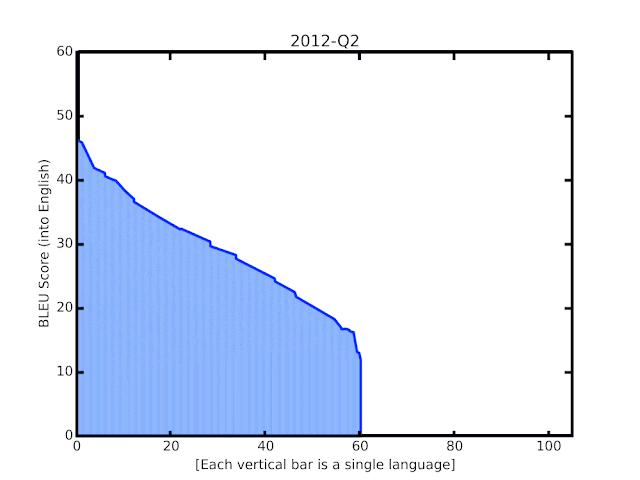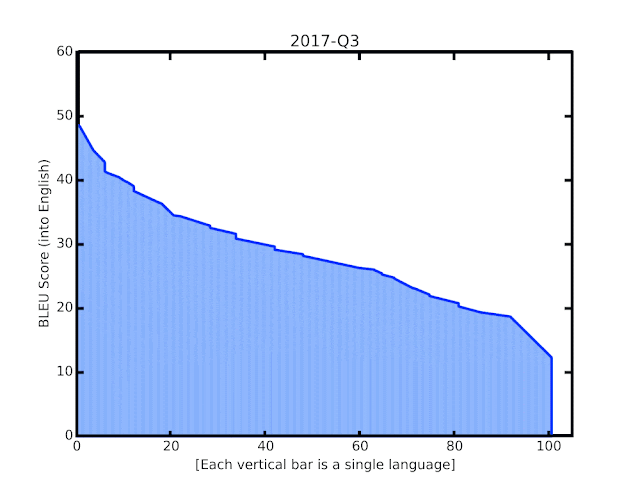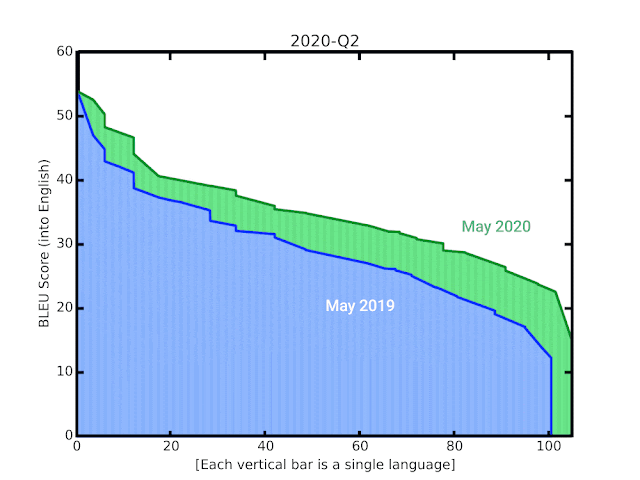
In this post, we share some recent progress we have made in translation quality for supported languages, especially for those that are low-resource, by synthesizing and expanding a variety of recent advances, and demonstrate how they can be applied at scale to noisy, web-mined data. These techniques span improvements to model architecture and training, improved treatment of noise in datasets, increased multilingual transfer learning through M4 modeling, and use of monolingual data. The quality improvements, which averaged +5 BLEU score over all 100+ languages, are visualized below.
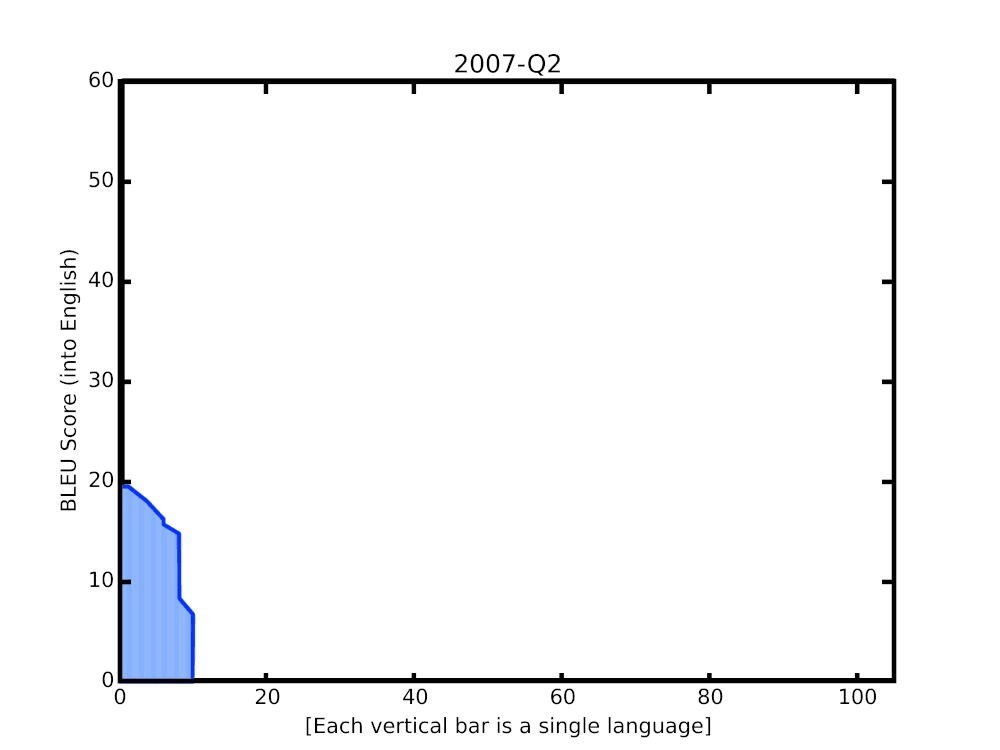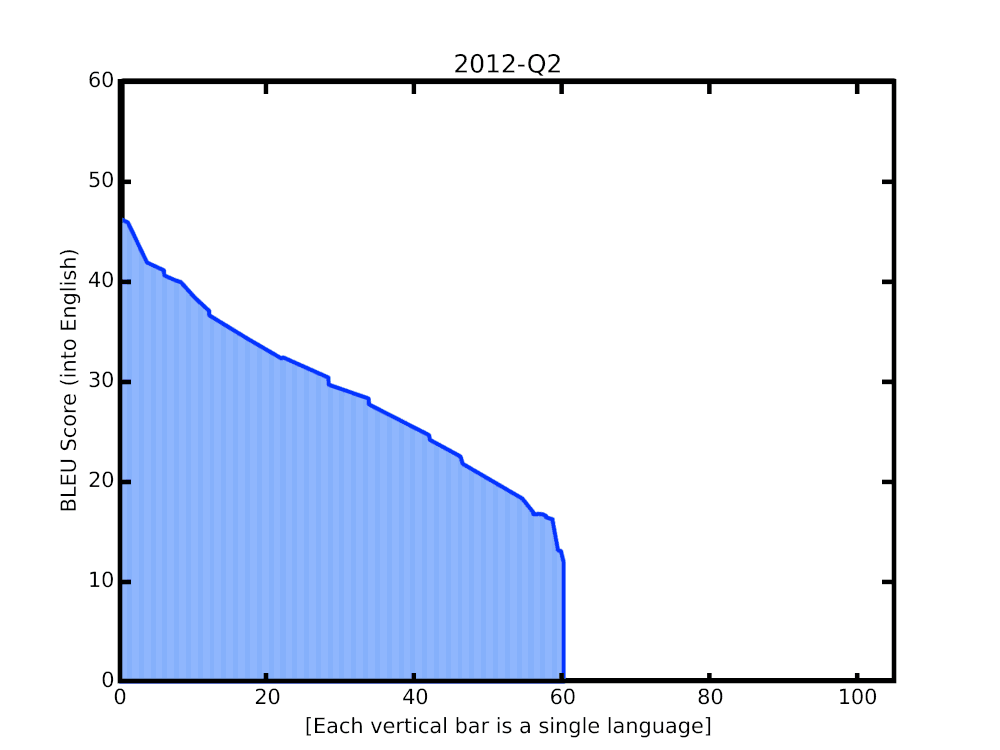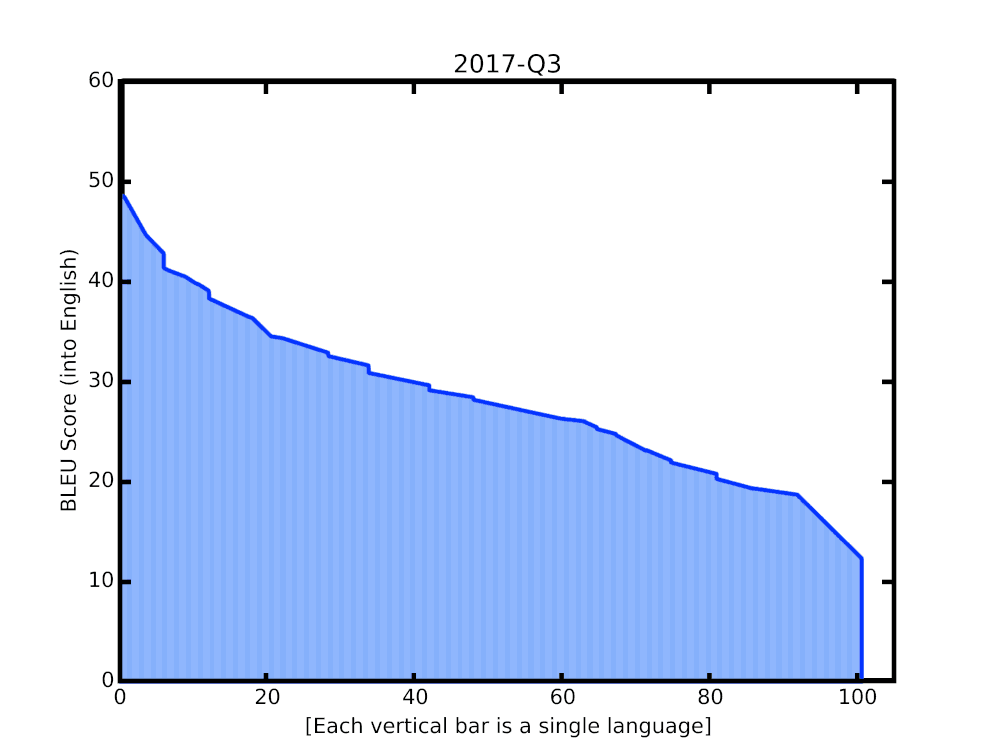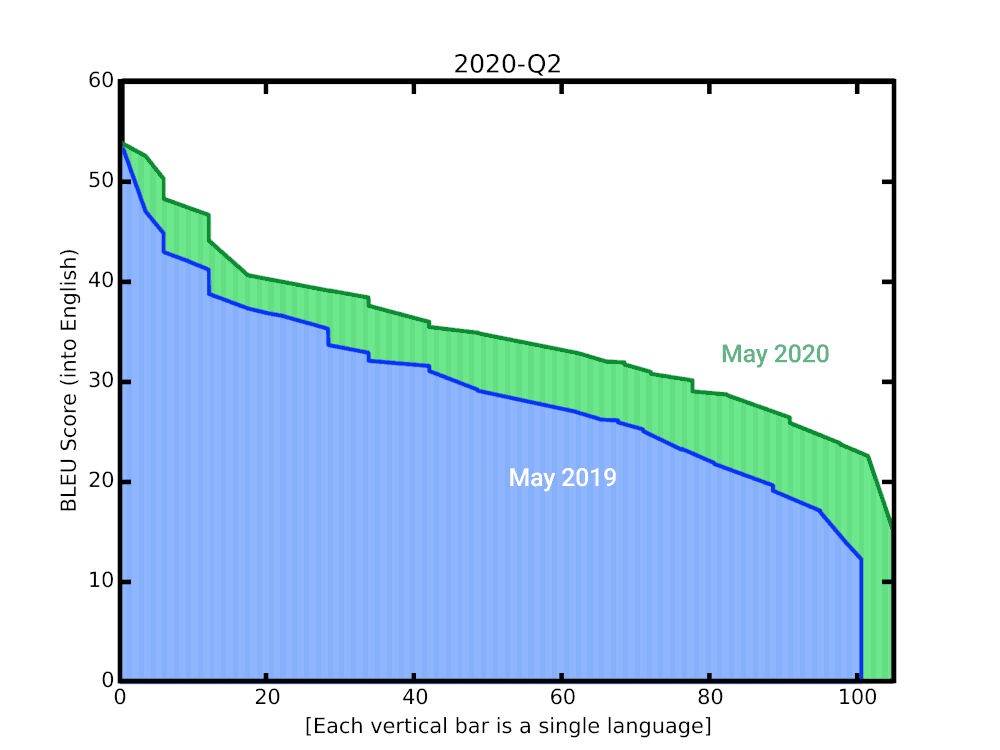 |
| BLEU score of Google Translate models since shortly after its inception in 2006. The improvements since the implementation of the new techniques over the last year are highlighted at the end of the animation. |
Advances for Both High- and Low-Resource Languages
Hybrid Model Architecture
Four years ago we introduced the RNN-based GNMT model, which yielded large quality improvements and enabled Translate to cover many more languages. Following our work decoupling different aspects of model performance, we have replaced the original GNMT system, instead training models with a transformer encoder and an RNN decoder, implemented in Lingvo (a TensorFlow framework). Transformer models have been demonstrated to be generally more effective at machine translation than RNN models, but our work suggested that most of these quality gains were from the transformer encoder, and that the transformer decoder was not significantly better than the RNN decoder. Since the RNN decoder is much faster at inference time, we applied a variety of optimizations before coupling it with the transformer encoder. The resulting hybrid models are higher-quality, more stable in training, and exhibit lower latency.
Web Crawl
Neural Machine Translation (NMT) models are trained using examples of translated sentences and documents, which are typically collected from the public web. Compared to phrase-based machine translation, NMT has been found to be more sensitive to data quality. As such, we replaced the previous data collection system with a new data miner that focuses more on precision than recall, which allows the collection of higher quality training data from the public web. Additionally, we switched the web crawler from a dictionary-based model to an embedding based model for 14 large language pairs, which increased the number of sentences collected by an average of 29 percent, without loss of precision.
Modeling Data Noise:
Data with significant noise is not only redundant but also lowers the quality of models trained on it. In order to address data noise, we used our results on denoising NMT training to assign a score to every training example using preliminary models trained on noisy data and fine-tuned on clean data. We then treat training as a curriculum learning problem — the models start out training on all data, and then gradually train on smaller and cleaner subsets.
Advances That Benefited Low-Resource Languages in Particular
Back-Translation
Widely adopted in state-of-the-art machine translation systems, back-translation is especially helpful for low-resource languages, where parallel data is scarce. This technique augments parallel training data (where each sentence in one language is paired with its translation) with synthetic parallel data, where the sentences in one language are written by a human, but their translations have been generated by a neural translation model. By incorporating back-translation into Google Translate, we can make use of the more abundant monolingual text data for low-resource languages on the web for training our models. This is especially helpful in increasing fluency of model output, which is an area in which low-resource translation models underperform.
M4 Modeling
A technique that has been especially helpful for low-resource languages has been M4, which uses a single, giant model to translate between all languages and English. This allows for transfer learning at a massive scale. As an example, a lower-resource language like Yiddish has the benefit of co-training with a wide array of other related Germanic languages (e.g., German, Dutch, Danish, etc.), as well as almost a hundred other languages that may not share a known linguistic connection, but may provide useful signal to the model.
Judging Translation Quality
A popular metric for automatic quality evaluation of machine translation systems is the BLEU score, which is based on the similarity between a system’s translation and reference translations that were generated by people. With these latest updates, we see an average BLEU gain of +5 points over the previous GNMT models, with the 50 lowest-resource languages seeing an average gain of +7 BLEU. This improvement is comparable to the gain observed four years ago when transitioning from phrase-based translation to NMT.
Although BLEU score is a well-known approximate measure, it is known to have various pitfalls for systems that are already high-quality. For instance, several works have demonstrated how the BLEU score can be biased by translationese effects on the source side or target side, a phenomenon where translated text can sound awkward, containing attributes (like word order) from the source language. For this reason, we performed human side-by-side evaluations on all new models, which confirmed the gains in BLEU.
In addition to general quality improvements, the new models show increased robustness to machine translation hallucination, a phenomenon in which models produce strange “translations” when given nonsense input. This is a common problem for models that have been trained on small amounts of data, and affects many low-resource languages. For example, when given the string of Telugu characters “ష ష ష ష ష ష ష ష ష ష ష ష ష ష ష”, the old model produced the nonsensical output “Shenzhen Shenzhen Shaw International Airport (SSH)”, seemingly trying to make sense of the sounds, whereas the new model correctly learns to transliterate this as “Sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh”.
Conclusion
Although these are impressive strides forward for a machine, one must remember that, especially for low-resource languages, automatic translation quality is far from perfect. These models still fall prey to typical machine translation errors, including poor performance on particular genres of subject matter (“domains”), conflating different dialects of a language, producing overly literal translations, and poor performance on informal and spoken language.
Nonetheless, with this update, we are proud to provide automatic translations that are relatively coherent, even for the lowest-resource of the 108 supported languages. We are grateful for the research that has enabled this from the active community of machine translation researchers in academia and industry.
Acknowledgements
This effort is built on contributions from Tao Yu, Ali Dabirmoghaddam, Klaus Macherey, Pidong Wang, Ye Tian, Jeff Klingner, Jumpei Takeuchi, Yuichiro Sawai, Hideto Kazawa, Apu Shah, Manisha Jain, Keith Stevens, Fangxiaoyu Feng, Chao Tian, John Richardson, Rajat Tibrewal, Orhan Firat, Mia Chen, Ankur Bapna, Naveen Arivazhagan, Dmitry Lepikhin, Wei Wang, Wolfgang Macherey, Katrin Tomanek, Qin Gao, Mengmeng Niu, and Macduff Hughes.
Quick links
Other posts of interest
-

May 14, 2025
Deeper insights into retrieval augmented generation: The role of sufficient context- Data Mining & Modeling ·
- Generative AI ·
- Machine Intelligence
-
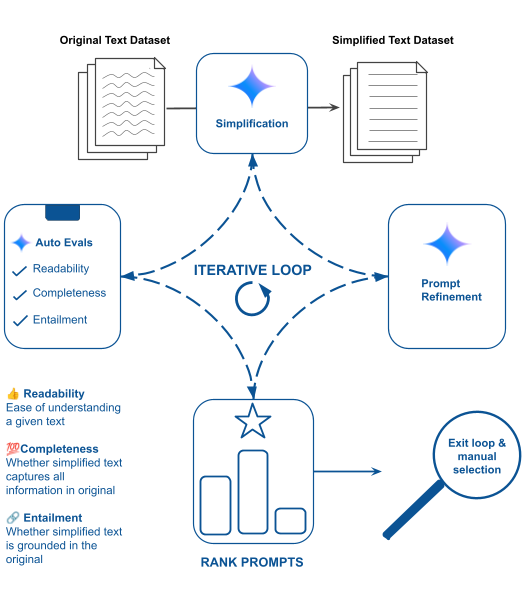
May 6, 2025
Making complex text understandable: Minimally-lossy text simplification with Gemini- Generative AI ·
- Health & Bioscience ·
- Product
-
April 23, 2025
Introducing Mobility AI: Advancing urban transportation- Algorithms & Theory ·
- General Science ·
- Machine Intelligence