SpineNet: A Novel Architecture for Object Detection Discovered with Neural Architecture Search
June 30, 2020
Posted by Xianzhi Du, Software Engineer and Jaeyoun Kim, Technical Program Manager, Google Research
Quick links
Convolutional neural networks created for image tasks typically encode an input image into a sequence of intermediate features that capture the semantics of an image (from local to global), where each subsequent layer has a lower spatial dimension. However, this scale-decreased model may not be able to deliver strong features for multi-scale visual recognition tasks where recognition and localization are both important (e.g., object detection and segmentation). Several works including FPN and DeepLabv3+ propose multi-scale encoder-decoder architectures to address this issue, where a scale-decreased network (e.g., a ResNet) is taken as the encoder (commonly referred to as a backbone model). A decoder network is then applied to the backbone to recover the spatial information.
While this architecture has yielded improved success for image recognition and localization tasks, it still relies on a scale-decreased backbone that throws away spatial information by down-sampling, which the decoder then must attempt to recover. What if one were to design an alternate backbone model that avoids this loss of spatial information, and is thus inherently well-suited for simultaneous image recognition and localization?
In our recent CVPR 2020 paper “SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization”, we propose a meta architecture called a scale-permuted model that enables two major improvements on backbone architecture design. First, the spatial resolution of intermediate feature maps should be able to increase or decrease anytime so that the model can retain spatial information as it grows deeper. Second, the connections between feature maps should be able to go across feature scales to facilitate multi-scale feature fusion. We then use neural architecture search (NAS) with a novel search space design that includes these features to discover an effective scale-permuted model. We demonstrate that this model is successful in multi-scale visual recognition tasks, outperforming networks with standard, scale-reduced backbones. To facilitate continued work in this space, we have open sourced the SpineNet code to the Tensorflow TPU GitHub repository in Tensorflow 1 and TensorFlow Model Garden GitHub repository in Tensorflow 2.
 |
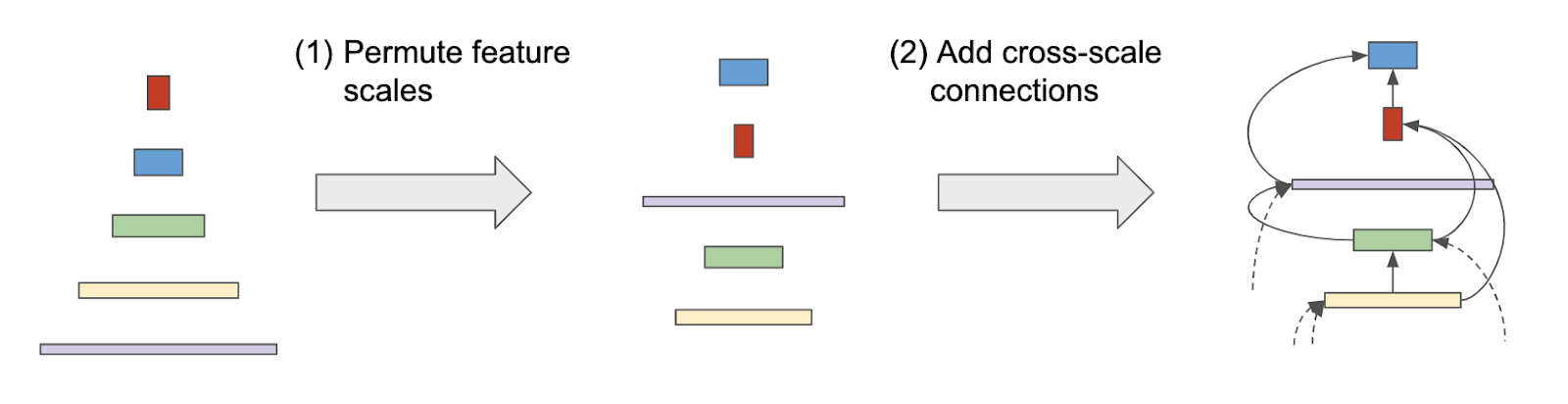
| A scale-decreased backbone is shown on the left and a scale-permuted backbone is shown on the right. Each rectangle represents a building block. Colors and shapes represent different spatial resolutions and feature dimensions. Arrows represent connections among building blocks. |
In order to efficiently design the architecture for SpineNet, and avoid a time-intensive manual search of what is optimal, we leverage NAS to determine an optimal architecture. The backbone model is learned on the object detection task using the COCO dataset, which requires simultaneous recognition and localization. During architecture search, we learn three things:
- Scale permutations: The orderings of network building blocks are important because each block can only be built from those that already exist (i.e., with a “lower ordering”). We define the search space of scale permutations by rearranging intermediate and output blocks, respectively.
- Cross-scale connections: We define two input connections for each block in the search space. The parent blocks can be any block with a lower ordering or a block from the stem network.
- Block adjustments (optional): We allow the block to adjust its scale level and type.
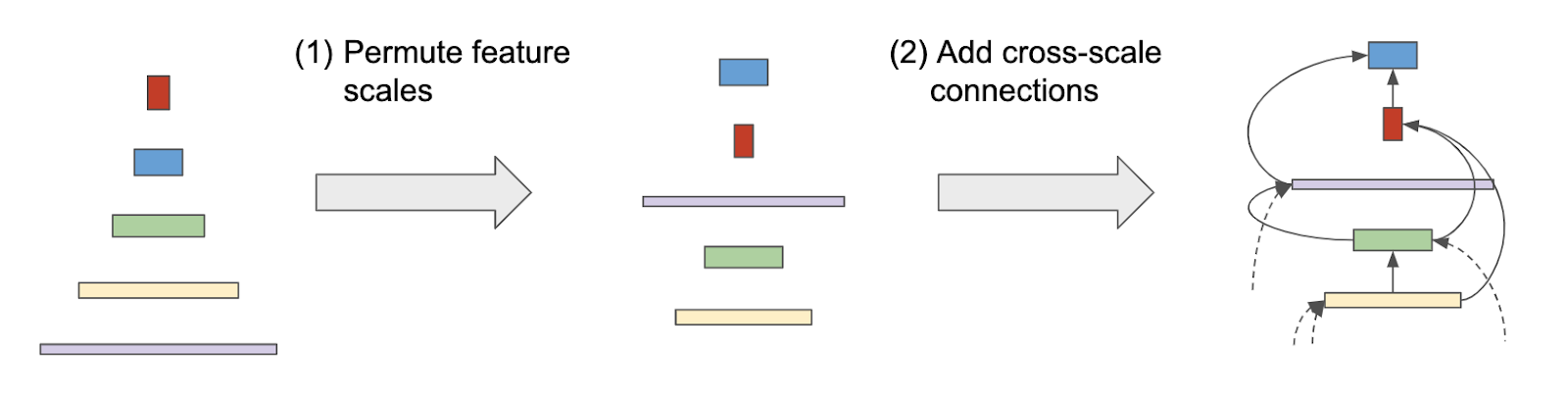 |
| The architecture search process from a scale-decreased backbone to a scale-permuted backbone. |
We name the learned 49-layer scale-permuted backbone architecture SpineNet-49. SpineNet-49 can be further scaled up to SpineNet-96/143/190 by repeating blocks two, three, or four times and increasing the feature dimension. An architecture comparison between ResNet-50-FPN and the final SpineNet-49 is shown below.
 |
| The architecture comparison between a ResNet backbone (left) and the SpineNet backbone (right) derived from it using NAS. |
We demonstrate the performance of SpineNet models through comparison with ResNet-FPN. Using similar building blocks, SpineNet models outperform their ResNet-FPN counterparts by ~3% AP at various scales while using 10-20% fewer FLOPs. In particular, our largest model, SpineNet-190, achieves 52.1% AP on COCO for a single model without multi-scale testing during inference, significantly outperforming prior detectors. SpineNet also transfers to classification tasks, achieving 5% top-1 accuracy improvement on the challenging iNaturalist fine-grained dataset. (Edit 2020-12-12: Experiment results on COCO can be viewed and downloaded on TensorBoard.dev. Metric definitions and naming conventions correspond directly to those defined by COCO. Terminal values on TensorBoard may exceed those in the below table due to TF1 to TF2 conversion, and as a consequence of a series of random variants in the pipeline.)
 |
| Performance comparisons of SpineNet models and ResNet-FPN models adopting the RetinaNet detection framework on COCO bounding box detection. |
 |
| Performance comparisons of SpineNet models and ResNet models on ImageNet classification and iNaturalist fine-grained image classification. |
In this work, we identify that the conventional scale-decreased model, even with a decoder network, is not effective for simultaneous recognition and localization. We propose the scale-permuted model, a new meta-architecture, to address the issue. To prove the effectiveness of scale-permuted models, we learn SpineNet by Neural Architecture Search in object detection and demonstrate it can be used directly in image classification. In the future, we hope the scale-permuted model will become the meta-architecture design of backbones across many visual tasks beyond detection and classification.
Acknowledgements
Special thanks to the co-authors of the paper: Tsung-Yi Lin, Pengchong Jin, Golnaz Ghiasi, Mingxing Tan, Yin Cui, Quoc V. Le, and Xiaodan Song. We also would like to acknowledge Yeqing Li, Youlong Cheng, Jing Li, Jianwei Xie, Russell Power, Hongkun Yu, Chad Richards, Liang-Chieh Chen, Anelia Angelova, and the larger Google Brain Team for their help.
Quick links
Other posts of interest
-
April 8, 2025
Geospatial Reasoning: Unlocking insights with generative AI and multiple foundation models- Climate & Sustainability ·
- Generative AI ·
- Machine Perception
-
February 28, 2025
Mind the GAP: Geometry Aware Passthrough mitigates cybersickness- Human-Computer Interaction and Visualization ·
- Machine Perception
-
December 4, 2024
Extending video masked autoencoders to 128 frames- Machine Intelligence ·
- Machine Perception