Unlocking the Full Potential of Datacenter ML Accelerators with Platform-Aware Neural Architecture Search
February 8, 2022
Posted by Sheng Li, Staff Software Engineer and Norman P. Jouppi, Google Fellow, Google Research
Continuing advances in the design and implementation of datacenter (DC) accelerators for machine learning (ML), such as TPUs and GPUs, have been critical for powering modern ML models and applications at scale. These improved accelerators exhibit peak performance (e.g., FLOPs) that is orders of magnitude better than traditional computing systems. However, there is a fast-widening gap between the available peak performance offered by state-of-the-art hardware and the actual achieved performance when ML models run on that hardware.
One approach to address this gap is to design hardware-specific ML models that optimize both performance (e.g., throughput and latency) and model quality. Recent applications of neural architecture search (NAS), an emerging paradigm to automate the design of ML model architectures, have employed a platform-aware multi-objective approach that includes a hardware performance objective. While this approach has yielded improved model performance in practice, the details of the underlying hardware architecture are opaque to the model. As a result, there is untapped potential to build full capability hardware-friendly ML model architectures, with hardware-specific optimizations, for powerful DC ML accelerators.
In “Searching for Fast Model Families on Datacenter Accelerators”, published at CVPR 2021, we advanced the state of the art of hardware-aware NAS by automatically adapting model architectures to the hardware on which they will be executed. The approach we propose finds optimized families of models for which additional hardware performance gains cannot be achieved without loss in model quality (called Pareto optimization). To accomplish this, we infuse a deep understanding of hardware architecture into the design of the NAS search space for discovery of both single models and model families. We provide quantitative analysis of the performance gap between hardware and traditional model architectures and demonstrate the advantages of using true hardware performance (i.e., throughput and latency), instead of the performance proxy (FLOPs), as the performance optimization objective. Leveraging this advanced hardware-aware NAS and building upon the EfficientNet architecture, we developed a family of models, called EfficientNetX, that demonstrate the effectiveness of this approach for Pareto-optimized ML models on TPUs and GPUs.
Platform-Aware NAS for DC ML Accelerators
To achieve high performance, ML models need to adapt to modern ML accelerators. Platform-aware NAS integrates knowledge of the hardware accelerator properties into all three pillars of NAS: (i) the search objectives; (ii) the search space; and (iii) the search algorithm (shown below). We focus on the new search space because it contains the building blocks needed to compose the models and is the key link between the ML model architectures and accelerator hardware architectures.
We construct TPU/GPU specialized search spaces with TPU/GPU-friendly operations to infuse hardware awareness into NAS. For example, a key adaptation is maximizing parallelism to ensure different hardware components inside the accelerators work together as efficiently as possible. This includes the matrix multiplication units (MXUs) in TPUs and the TensorCore in GPUs for matrix/tensor computation, as well as the vector processing units (VPUs) in TPUs and CUDA cores in GPUs for vector processing. Maximizing model arithmetic intensity (i.e., optimizing the parallelism between computation and operations on the high bandwidth memory) is also critical to achieve top performance. To tap into the full potential of the hardware, it is crucial for ML models to achieve high parallelism inside and across these hardware components.
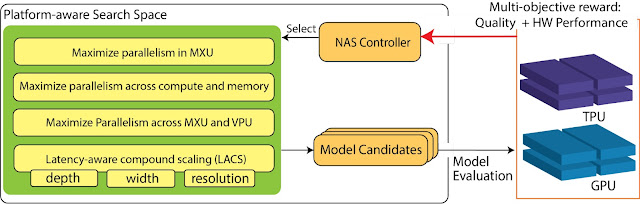 |
| Overview of platform-aware NAS on TPUs/GPUs, highlighting the search space and search objectives. |
Advanced platform-aware NAS has an optimized search space containing a set of complementary techniques to holistically improve parallelism for ML model execution on TPUs and GPUs:
- It uses specialized tensor reshaping techniques to maximize the parallelism in the MXUs / TensorCores.
- It dynamically selects different activation functions depending on matrix operation types to ensure overlapping of vector and matrix/tensor processing.
- It employs hybrid convolutions and a novel fusion strategy to strike a balance between total compute and arithmetic intensity to ensure that computation and memory access happens in parallel and to reduce the contention on VPUs / CUDA cores.
- With latency-aware compound scaling (LACS), which uses hardware performance instead of FLOPs as the performance objective to search for model depth, width and resolutions, we ensure parallelism at all levels for the entire model family on the Pareto-front.
EfficientNet-X: Platform-Aware NAS-Optimized Computer Vision Models for TPUs and GPUs
Using this approach to platform-aware NAS, we have designed EfficientNet-X, an optimized computer vision model family for TPUs and GPUs. This family builds upon the EfficientNet architecture, which itself was originally designed by traditional multi-objective NAS without true hardware-awareness as the baseline. The resulting EfficientNet-X model family achieves an average speedup of ~1.5x–2x over EfficientNet on TPUv3 and GPUv100, respectively, with comparable accuracy.
In addition to the improved speeds, EfficientNet-X has shed light on the non-proportionality between FLOPs and true performance. Many think FLOPs are a good ML performance proxy (i.e., FLOPs and performance are proportional), but they are not. While FLOPs are a good performance proxy for simple hardware such as scalar machines, they can exhibit a margin of error of up to 400% on advanced matrix/tensor machines. For example, because of its hardware-friendly model architecture, EfficientNet-X requires ~2x more FLOPs than EfficientNet, but is ~2x faster on TPUs and GPUs.
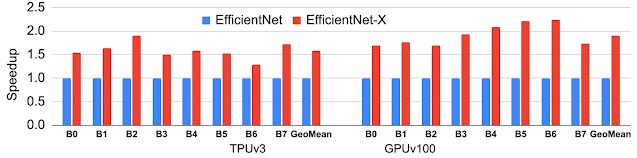 |
| EfficientNet-X family achieves 1.5x–2x speedup on average over the state-of-the-art EfficientNet family, with comparable accuracy on TPUv3 and GPUv100. |
Self-Driving ML Model Performance on New Accelerator Hardware Platforms
Platform-aware NAS exposes the inner workings of the hardware and leverages these properties when designing hardware-optimized ML models. In a sense, the “platform-awareness” of the model is a “gene” that preserves knowledge of how to optimize performance for a hardware family, even on new generations, without the need to redesign the models. For example, TPUv4i delivers up to 3x higher peak performance (FLOPS) than its predecessor TPUv2, but EfficientNet performance only improves by 30% when migrating from TPUv2 to TPUv4i. In comparison, EfficientNet-X retains its platform-aware properties even on new hardware and achieves a 2.6x speedup when migrating from TPUv2 to TPUv4i, utilizing almost all of the 3x peak performance gain expected when upgrading between the two generations.
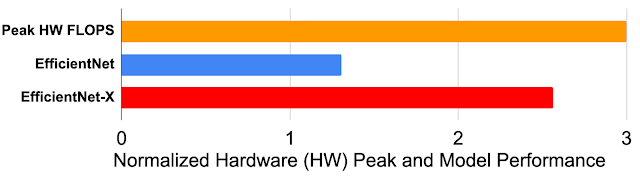 |
| Hardware peak performance ratio of TPUv2 to TPUv4i and the geometric mean speedup of EfficientNet-X and EfficientNet families, respectively, when migrating from TPUv2 to TPUv4i. |
Conclusion and Future Work
We demonstrate how to improve the capabilities of platform-aware NAS for datacenter ML accelerators, especially TPUs and GPUs. Both platform-aware NAS and the EfficientNet-X model family have been deployed in production and materialize up to ~40% efficiency gains and significant quality improvements for various internal computer vision projects across Google. Additionally, because of its deep understanding of accelerator hardware architecture, platform-aware NAS was able to identify critical performance bottlenecks on TPUv2-v4i architectures and has enabled design enhancements to future TPUs with significant potential performance uplift. As next steps, we are working on expanding platform-aware NAS’s capabilities to the ML hardware and model design beyond computer vision.
Acknowledgements
Special thanks to our co-authors: Mingxing Tan, Ruoming Pang, Andrew Li, Liqun Cheng, Quoc Le. We also thank many collaborators including Jeff Dean, David Patterson, Shengqi Zhu, Yun Ni, Gang Wu, Tao Chen, Xin Li, Yuan Qi, Amit Sabne, Shahab Kamali, and many others from the broad Google research and engineering teams who helped on the research and the subsequent broad production deployment of platform-aware NAS.
Other posts of interest
-

April 19, 2024
Improving Gboard language models via private federated analytics- Algorithms & Theory ·
- Distributed Systems & Parallel Computing ·
- Product ·
- Security, Privacy and Abuse Prevention
-

April 17, 2024
Robust speech recognition in AR through infinite virtual rooms with acoustic modeling- Human-Computer Interaction and Visualization ·
- Machine Perception ·
- Speech Processing
-
March 18, 2024
MELON: Reconstructing 3D objects from images with unknown poses- Machine Intelligence ·
- Machine Perception