FRILL: On-Device Speech Representations using TensorFlow-Lite
June 10, 2021
Posted by Joel Shor, Software Engineer, Google Research, Tokyo and Sachin Joglekar, Software Engineer, TensorFlow
Quick links
Representation learning is a machine learning (ML) method that trains a model to identify salient features that can be applied to a variety of downstream tasks, ranging from natural language processing (e.g., BERT and ALBERT) to image analysis and classification (e.g., Inception layers and SimCLR). Last year, we introduced a benchmark for comparing speech representations and a new, generally-useful speech representation model (TRILL). TRILL is based on temporal proximity, and tries to map speech that occurs close together in time to a lower-dimensional embedding that captures temporal proximity in the embedding space. Since its release, the research community has used TRILL on a diverse set of tasks, such as age classification, video thumbnail selection, and language identification. However, despite achieving state-of-the-art performance, TRILL and other neural network-based approaches require more memory and take longer to compute than signal processing operations that deal with simple features, like loudness, average energy, pitch, etc.
In our recent paper "FRILL: A Non-Semantic Speech Embedding for Mobile Devices", to appear at Interspeech 2021, we create a new model that is 40% the size of TRILL and and a feature set that can be computed over 32x faster on mobile phone, with an average decrease in accuracy of less than 2%. This marks an important step towards fully on-device applications of speech ML models, which will lead to better personalization, improved user experiences and greater privacy, an important aspect of developing AI responsibly. We release the code to create FRILL on github, and a pre-trained FRILL model on TensorFlow Hub.
FRILL: Smaller, Faster TRILL
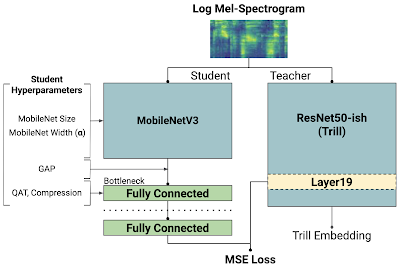
The TRILL architecture is based on a modified version of ResNet50, an architecture that is computationally taxing for constrained hardware, like mobile phones or smart home devices. On the other hand, architectures like MobileNetV3 have been designed with hardware-aware AutoML to perform well on mobile devices. To take advantage of this, we leverage knowledge distillation to combine the benefits of MobileNetV3’s performance with TRILL’s representations.
In the distillation process, the smaller model (i.e., the "student") tries to match the output of the larger model ("teacher") on the AudioSet dataset. Whereas the original TRILL model learned its weights by optimizing a self-supervised loss that clustered audio segments close in time, the student model learns its weights through a fully-supervised loss that ignores temporal matching and instead tries to match TRILL outputs on the training data. The fully-supervised learning signal is often stronger than self-supervision, and allows us to train more quickly.
 |
| Knowledge distillation for non-semantic speech embeddings. The dashed line shows the student model output. The "teacher network" is the TRILL network, where "Layer 19" was the best-performing internal representation. The "Student Hyperparameters" on the left are the options explored in this study, the result of which are 144 distinct models. These models were trained with mean-squared error (MSE) to try to match TRILL's Layer 19. |
Choosing the Best Student Model
We perform distillation with a variety of student models, each trained with a specific combination of architecture choices (explained below). To measure each student model’s latency, we leverage TensorFlow Lite (TFLite), a framework that enables execution of TensorFlow models on edge devices. Each candidate model is first converted into TFLite’s flatbuffer format for 32-bit floating point inference and then sent to the target device (in this case, a Pixel 1) for benchmarking. These measurements help us to accurately assess the latency versus quality tradeoffs across all student models and to minimize the loss of quality in the conversion process.
Architecture Choices and Optimizations
We explored different neural network architectures and features that balance latency and accuracy — models with fewer parameters are usually smaller and faster, but have less representational power and therefore generate less generally-useful representations. We trained 144 different models across a number of hyperparameters, all based on the MobileNetV3 architecture:
- MobileNetV3 size and width: MobileNetV3 was released in different sizes for use in different environments. The size refers to which MobileNetV3 architecture we used. The width, sometimes known as alpha, proportionally decreases or increases the number of filters in each layer. A width of 1.0 corresponds to the number of filters in the original paper.
- Global average pooling: MobileNetV3 normally produces a set of two-dimensional feature maps. These are flattened, concatenated, and passed to the bottleneck layer. However, this bottleneck is often still too large to be computed quickly. We reduce the size of the bottleneck layer kernel by taking the global average of all ”pixels” in each output feature map. Our intuition is that the discarded temporal information is less important for learning a non-semantic speech representation due to the fact that relevant aspects of the signal are stable across time.
- Bottleneck compression: A significant portion of the student model’s weights are located in the bottleneck layer. To reduce the size of this layer, we apply a compression operator based on singular value decomposition (SVD) that learns a low-rank approximation of the bottleneck weight matrix.
- Quantization-aware training: Since the bottleneck layer has most of the model weights, we use quantization-aware training (QAT) to gradually reduce the numerical precision of the bottleneck weights during training. QAT allows the model to adjust to the lower numerical precision during training, instead of potentially causing performance degradation by introducing quantization after training finishes.
Results
We evaluated each of these models on the Non-Semantic Speech Benchmark (NOSS) and two new tasks — a challenging task to detect whether a speaker is wearing a mask and the human-noise subset of the Environment Sound Classification dataset, which includes labels like “coughing” and “sneezing”. After eliminating models that have strictly better alternatives, we are left with eight ”frontier” models on the quality vs. latency curve, which are the models that had no faster and better performance alternatives at a corresponding quality threshold or latency in our batch of 144 models. We plot the latency vs. quality curve of only these "frontier" models below, and we ignore models that are strictly worse.
 |
| Embedding quality and latency tradeoff. The x-axis represents the inference latency and the y-axis shows the difference in accuracy from TRILL’s performance, averaged across benchmark datasets. |
FRILL is the best performing sub-10ms inference model, with an inference time of 8.5 ms on a Pixel 1 (about 32x faster than TRILL), and is also roughly 40% the size of TRILL. The frontier curve plateaus at about 10ms latency, which means that at low latency, one can achieve much better performance with minimal latency costs, while achieving improved performance at latencies beyond 10ms is more difficult. This supports our choice of experiment hyperparameters. FRILL's per-task performance is shown in the table below.
| FRILL | TRILL | |
| Size (MB) | 38.5 | 98.1 |
| Latency (ms) | 8.5 | 275.3 |
| Voxceleb1* | 45.5 | 46.8 |
| Voxforge | 78.8 | 84.5 |
| Speech Commands | 81.0 | 81.7 |
| CREMA-D | 71.3 | 65.9 |
| SAVEE | 63.3 | 70.0 |
| Masked Speech | 68.0 | 65.8 |
| ESC-50 HS | 87.9 | 86.4 |
| Accuracy on each of the classification tasks (higher is better). *Results in our study use a small subset of Voxceleb1 filtered according to internal privacy guidelines. Interested readers can run our study on the full dataset using TensorFlow Datasets and our open-source evaluation code. |
Finally, we evaluate the relative contribution of each of our hyperparameters. We find that for our experiments, quantization-aware training, bottleneck compression and global average pooling most reduced the latency of the resulting models. At the same time bottleneck compression most reduced the quality of the resulting model, while pooling reduced the model performance the least. The architecture width parameter was an important factor in reducing the model size, with minimal performance degradation.
 |
| Linear regression weight magnitudes for predicting model quality, latency, and size. The weights indicate the expected impact of changing the input hyperparameter. A higher weight magnitude indicates a greater expected impact. |
Our work is an important step in bringing the full benefits of speech machine learning research to mobile devices. We also provide our public model, corresponding model card, and evaluation code to help the research community responsibly develop even more applications for on-device speech representation research.
Acknowledgements
We'd like to thank our paper co-authors: Jacob Peplinski, Jake Garrison and Shwetak Patel. We'd like to thank Aren Jansen for his technical support on this project, Françoise Beaufays, and Tulsee Doshi for help open sourcing the model, and Google Research, Tokyo for logistical support.
Quick links
Other posts of interest
-

August 7, 2025
Achieving 10,000x training data reduction with high-fidelity labels- Human-Computer Interaction and Visualization ·
- Machine Intelligence ·
- Security, Privacy and Abuse Prevention
-

August 6, 2025
Insulin resistance prediction from wearables and routine blood biomarkers- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence
-

August 1, 2025
MLE-STAR: A state-of-the-art machine learning engineering agent- Machine Intelligence